PROPOJENÍ ANALYTICKÝCH ZÁZNAMŮ S PLNÝMI TEXTY |
Zpracovala: PhDr. Ivana Anděrová, hlavní řešitelka
Technická redakce Denisa Molitorisová
OBSAH
A |
Konstatační část |
| A.1 | Rešerše |
| A.2 | Současný stav ve světě a v ČR |
| A.3 | Cíl, vstupní data |
B |
Analytická část |
| B.1 | Vlastní řešení |
| B.1.1 | Vlastní řešení v komplexním pohledu |
| B.1.2 | Plnění úkolů v jednotlivých letech |
| B.2 | Přínos řešitele |
| B.3 | Posun znalostí |
C |
Návrhová část |
| C.1 | Výsledky řešení |
| C.2 | Závěr |
| C.3 | Návrhy opatření |
D |
Použití finančních prostředků |
E |
Resumé a klíčová slova |
| E.1 | Resumé a klíčová slova v češtině |
| E.2 | Abstract and key words in English |
F |
Přílohy |
| F.1 | Příloha F 1 : Statistiky propojení na plné texty vydané v příslušných letech |
| F.2 | Příloha F 2 : optimalizace zpřístupnění plných textů |
| F.3 | Příloha F 3 : Smlouva konzorcium Anopress (pouze v tištěné podobě) |
| F.4 | Příloha F 4 : Licence VIS (TOPIC-Portal One) (pouze v tištěné podobě) |
A Konstatační část
A.1 Rešerše
Pozn.: v současné době je web NKČR v rekonstrukci. Uvádím adresy platné v lednu 2004, budoucí mi nejsou známy. Z toho důvodu nebudou některé odkazy ve zprávě na tento web patrně nějakou dobu funkční.
CÍGLER, I., Königová, M., Lukavec, P., Vacek, V. Hodnocení efektivnosti informačních systémů. Systémová analýza v informatice. ČVTS, 1974. S. 98-115.
SARACEVIC, T. The concept of relevance in information science : a historical review. Introduction to Information Science. New York : Academic Press, 1976. S. 79-137.
ZEMANOVÁ, I. Problematika relevance a pertinence. Vývoj a současný stav. Diplomová práce. Praha. FFUK , 1977. 164 s.
Analytický popis. Praha : Národní knihovna v Praze, 1991. 2 sv. + disketa. ( MAKS)
KOUDELKOVÁ, L. NÁDVORNÍKOVÁ, M. BAJÁK, M. Návod pro tvorbu a využívání báze záznamů dokumentů. Verze 1. Praha : Národní knihovna v Praze, 1991. 71 s. (MAKS)
STOKLASOVÁ, B., ANDĚROVÁ, I., KREMEROVÁ, J. Specifikace údajů pro bázi záznamů dokumentů. Verze 1. Praha : Národní knihovna v Praze, 1991. nestr. (MAKS)
ANDĚROVÁ, I. Pravidla zápisu údajů pro analytický popis. Praha : Národní knihovna v Praze, 1992. 217 s. + příl.
ANDĚROVÁ, I. [et al.]. Národní bibliografie - analytický popis : příručka pro zpracovatele. Praha : Národní knihovna, 1993. 412 s. Revize 1, 1993; Revize 2, 1997.
BÍNOVÁ, J.Regionální bibliografická činnost v SVK - možnosti spolupráce s okresními knihovnami. Čtenář, roč. 46, č. 2,1994, s. 45-48.
NÁDVORNÍKOVÁ, M. Spolupráce na úplnosti národní bibliografie z pohledu regionálních vědeckých knihoven. Knihovny současnosti '96.1. vyd. Brno : Sdružení knihoven, 1996, s. 134-139.
1996 Glenda Browne. To be published in Online Currents, the AusSI Newsletter 20(6):4-9, July 1996 and LASIE 27(3):58-65
Doporučení pro popis částí dokumentu na základě mezinárodního standardního bibliografického popisu (ISBD). 1. vyd. Praha: Národní knihovna ČR, 1997. 32 s.
Cobra+ : Computerised Bibliographic Record Actions [online]. Boston Spa (Velká Británie) : COBRA+, 1997. Dostupný z: http://www.ddb.de/gabriel/cobra.
KOCH, Traugott and BORELL, Maattias. Dublin Core Metadata Template [online]. Lund (Švédsko) : Lund universitetsbibliotek, 1997, last update 1997-08-20. Dostupný z URL: http://www.lub.lu.se/metadata/DC_creator.htm.
Nordic Countries URN-generator : provided by the Nordic Libraries [online]. Lund (Švédsko) : Lund universitetsbibliotek, 1997. Dostupný z URL: http://www.lub.lu.se/cgi-bin/nmurn.pl
OLSON, Nancy B. Cataloging Internet Resources [online]. Dublin (Ohio, USA) : OCLC, 1997. Dostupný z URL: http://www.oclc.org/support/documentation/worldcat/cataloging/internetguide/
BRATKOVÁ, Eva. Bibliografické a plnotextové báze dat americké firmy H.W.Wilson pro společenské a humanitní obory: vyhledávání informací v systému WilsonWeb. Infomedia [online], 1998. Dostupný z: URL: http://www.inforum.cz/infomedia98/pdf/wilson.htm.
BRATKOVÁ, Eva. K otázkám pojmu, třídění a typologie internetových a webovských informačních zdrojů. Národní knihovna : knihovnická revue, 1998, roč. 9, č. 5, s. 262-276. Dostupný z URL: http://full.nkp.cz/
JONÁK, Z. Inteligentní nástroje pro práci s texty na Internetu. Ikaros [online]. 1998, č. 09 [cit. 1998-09-01].Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200208003. ISSN 1212-5075.
BRATKOVÁ, Eva. Metadata jako nový nástroj pro komunikaci webovských informačních zdrojů. Národní knihovna : knihovnická revue, 1999, roč. 10, č. 4, s. 178-195. Dostupný též z URL: http://full.nkp.cz/nkkr/Nkkr9904/9904178.html.
ČERVENÝ, Vlastimil. Vyhledávání v databázích plných textů. Národní knihovna : knihovnická revue, 1999, roč. 10, č. 1, s. 6-12. Dostupný též z URL: http://full.nkp.cz/nkkr/Nkkr9901/9901006.html.
BARTOŠEK, M. Vyhledávání v Internetu a DUBLIN CORE. Zpravodaj ÚVT MU. ISSN 1212-0901, 1999, roč. 9, č. 4, s. 1-4.
Záznam pro soubornou databázi : UNIMARC. Fyzicky nesamostatné části dokumentů. Tištěné monografie a seriály. Pracovní skupina pro analytické zpracování, Rada pro katalogizační politiku. 1. vyd. Praha : Národní knihovna České republiky,1999. 45 s. (Standardizace ; č. 19). Určeno k připomínkám. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=fond_anal_unim_opr.htm
Záznam pro soubornou databázi : Výměnný formát. Fyzicky nesamostatné části dokumentů. Tištěné monografie a seriály. Pracovní skupina pro analytické zpracování, Rada pro katalogizační politiku. 1. vyd. Praha : Národní knihovna České republiky,1999. 39 s. (Standardizace ; č. 20). Určeno k připomínkám. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=fond_ann_vf_opr.htm
JONÁK, Z. Reflektuje teorie informace a komunikace dostatečně na zvýšený zájem společenských věd o semiotické a komunikační aspekty života? Ikaros [online]. 1999, č. 3 [cit. 1999-03-01]. Dostupný z URL: http://ikaros.ff.cuni.cz/1999/c03/veda2.htm. Pozn.: nepřístupný
JONÁK, Z. Krize mezilidské komunikace v období komunikační a informační exploze. Ikaros [online]. 1999, č. 05 [cit. 1999-05-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200205066. ISSN 1212-5075.
PAPÍK, R. Trendy v rozvoji informačních služeb. Ikaros [online]. 1999, č. 8 [cit. 1999-09-01]. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200208571.
SVOBODA, Martin. Elektronické publikování. Ikaros [online], 1999, č. 3. Dostupný z URL: http://ikaros.ff.cuni.cz/ikaros/1999/c03/elpubl98/index.htm. Pozn.: nepřístupný.
OPPENHEIM, Charles. SMITHSON, Daniel. What is the hybrid library? Journal of Information Science, 1999, vol. 25, no. 2, s. 97-112.
BURGETOVÁ, Jarmila. Právní aspekty poskytování knihovních elektronických a reprografických služeb. Ikaros [online], 1999, č. 6. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200205087.
HEIJTING, Inge. Interconnectivity and the Hybrid Library. Ikaros [online], 1999, č. 10. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200205142.
Projects at the Royal Library in Stockholm, Sweden [online]. Stockholm : Royal Library, updated July 1, 1999. Dostupný z URL: http://www.kb.se/ENG/projekt.htm.
Sborník příspěvků ze semináře CASLIN ´99 - Souborné katalogy:organizace a služby. Dostupný z URL: http://www.caslin.cz:7777/caslin99/prispevky.html.
TKAČÍKOVÁ, Daniela. Když se řekne digitální knihovna ... Ikaros [online], 1999, č. 8. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200208578.
Topic : systém pro inteligentní vyhledávání dokumentů. Praha : Tovek, 19?.
Uniform Resource Names (urn) Charter [online]. Reston (VA, USA) : IETF, last modified 03-Jun-99. Dostupný z URL: http://www.ietf.org/html.charters/OLD/urn-charter.html.
MOENS, M.F. Automatic indexing and abstracting of document texts. Boston : Kluwer Academic Publishers, 2000. 265 s.
PAPÍK, R. Competitive Intelligence, informační služby, Internet a informační profese. Ikaros [online]. 2001, č. 04 [cit. 2001-04-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200208281. ISSN 1212-5075.
JONÁK, Z. Inteligence systémů zpracování textů. Ikaros [online]. 2000, č. 1 [ cit. 2000-01-05]. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200209006.
ANDĚROVÁ, Ivana. Programový projekt MK ČR "Souborná databáze Kooperačního systému článkové bibliografie - optimalizace integrace a správy heterogenních dat". Ikaros [online]. 2000, č. 10 [cit. 2000-12-01]. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200301003. ISSN 1212-5075.Biblink [online]. Bath (Anglie) : UKOLN, last updated 12-Jul-2000 [cit. 14. 3. 2001]. Dostupné z URL: http://hosted.ukoln.ac.uk/biblink/.
CELBOVÁ, Ludmila. Elektronické zdroje publikované v síti Internet jako součást České národní bibliografie. Ikaros [online], 2000, č. 6. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200208144.
DOI, the Digital Object Identifier System [online]. Kidlington (Oxford, Velká Británie) : International DOI Foundation, 1998, updated 4 April 2000. Dostupný z URL: http://www.doi.org/.
Dublin Core Metadata Initiative [online]. Dublin (Ohio, USA) : OCLC, 2000. Dostupný z URL : http://purl.org/dc/.
HORA, Michal a RICHTER, Vít. Veřejné informační služby knihoven - nový program pro občany a knihovny. Ikaros [online], 2000, č. 8. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200208582.
Metadata [online]. Bath (Anglie) : UKOLN, last updated 16-Feb-2000. Dostupný z URL: http://www.ukoln.ac.uk/metadata/.
VOJTÁŠEK, Filip a CELBOVÁ, Iva. Helsinská univerzitní knihovna přívětivá vůči každému. Ikaros [online], 2000, č. 9. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200208199.
ŽABIČKA, Petr. Dublin Core - metadata pro popis elektronických dokumentů. Předneseno na konferenci DATASEM 2000, konané 21. až 24. října 2000 v Brně. Dostupné z URL: http://webarchiv.nkp.cz/datasem2000.pdf.
STOKLASOVÁ, B.:Budování a zpřístupnění fondů. Daidalos 2000. Dostupný z: http://daidalos.ff.cuni.cz/2000/prosinec/bs_ifla02.php.
Networked European Deposit Library [online]. Hague (Nizozemí) : Koninklijke Bibliotheek, last upd. 11-Mar-2001 [cit. 14. 3. 2001]. Dostupné z URL: http://www.kb.nl/nedlib/.
VEJLUPEK, T. SPEIS - koncept jednotného využívání a jednotné nabídky informačních zdrojů a informačních služeb od různých poskytovatelů. Praha , 2001. 18 s.
ANDĚROVÁ, I. Propojení analytických záznamů s plnými texty a optimalizace zpřístupnění plných textů. Souhrnná zpráva za rok ... [online]. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=oazp_granty.htm.
ANDĚROVÁ, I. Souborná databáze Kooperačního systému článkové bibliografie - optimalizace integrace a správy heterogenních dat. Souhrnná zpráva za rok # [online]. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=oazp_granty.htm.
ANDĚROVÁ, I. Kooperační sytém článkové bibliografie a propojení analytických záznamů s plnými texty - východiska a současný stav. Národní knihovna : knihovnická revue. 2001, roč. 12, č. 1, s. 26-37. Dostupný též z URL: http://full.nkp.cz/nkkr/NKKR0101/0101026.html.
PAPÍK, R. Competitive Intelligence, informační služby, Internet a informační profese. Ikaros [online]. 2001, č. 04 [cit. 2001-04-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200208281. ISSN 1212-5075.
ANDĚROVÁ, Ivana. Metodika popisu článků ve formátu UNIMARC [online]. 2001. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=oazp_popis1.htm.
CASLIN 2001. Popis a zpřístupnění dokumentů : nová výzva. Beroun, 27.-31. května 2001 [online]. Dostupný z URL: http://www.caslin.cz:7777/caslin01/index.htm
CELBOVÁ, Ludmila. Informace o projektu registrace domácích internetových zdrojů nově na serveru WebArchiv. Ikaros [online]. 2001, č. 5 [cit. 2001-05-01]. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200208297. ISSN 1212-5075.
CVRČKOVÁ, R. Služba GILS jako nástroj pro řízení informačních zdrojů z oblasti řízení státní správy USA. Národní knihovna : knihovnická revue. 2001, roč. 12, č.2, s. 99-113. Též dostupný z URL: http://full.nkp.cz/nkkr/NKKR0102/0102099.html.
SCHWARZ, J. (2001a). Praktické aspekty hodnocení kvality a konzistence indexace. Ikaros [online]. 2001, č. 2 [cit. 2001-02-01]. Dostupný z URL: http://www.ikaros.cz/Clanek.asp?ID=200303002
H.W. Wilson Company Selects Verity to Power the New WilsonWeb Site - the Premier Reference Resource for Librarians and Researchers [online]. Dostupný z URL: http://www.verity.com/company/press/2001/20010108.html.
Integration Heterogenous Resources : 25 Library Seminar, Prague 6-8 June 2001 [online]. Dostupný z URL: http://www.stk.cz/elag2001/ELAG2001.html
ANDĚROVÁ, I. Báze ANL FULL v systému TOPIC. Textová verze. Inforum 2002. Dostupný z URL: http://www.aip.cz/, http://full.nkp.cz/ .
ANDĚROVÁ, I. Báze ANL FULL v systému TOPIC. Prezentace PPT. Inforum 2002. Dostupný z URL: http://full.nkp.cz/ .
Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. Brno : Sdružení knihoven ČR, 2002. 401 s.
Knihovny současnosti 2002, Seč 24-26.9. 2002. PPT prezentace. Dostupný z URL: http://www.mzk.cz/aktivity/sec.php3 .
ANĎEROVÁ, I. Kooperační systém článkové bibliografie - KOSABI. (Vývoj a současný stav metodiky zpracování, zpřístupnění, organizace kooperace, perspektivy). Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. 2002, s. 223-255. Dostupný též z URL: http://full.nkp.cz/ .
ANDĚROVÁ, I. Kooperační systém článkové bibliografie - KOSABI. (Vývoj a současný stav metodiky zpracování, zpřístupnění, organizace kooperace, perspektivy ). Prezentace PPT na konferenci Knihovny současnosti 2002, Seč 24.-26.9.2002. Dostupný z URL: http://full.nkp.cz/ .
BÍNOVÁ, J.: Bibliografická sekce sdružení knihoven České republiky v letech 1995-2002. Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. 2002, s. 182-183.
NÁDVORNÍKOVÁ, M. Nové formy a metody práce při poskytování regionálních bibliografických informací. Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. 2002, s. 186-189. Dostupný též z URL: http://www.mzk.cz/aktivity/sec.php3
SVOBODOVÁ, E. Spolupráce paměťových institucí v rámci krajského bibliografického systému - Utopie. Nebo reálná možnost? Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. 2002, s. 190-194.
MIKA, J. Regionální bibliografie a faktografie - příklad spojení tradičního a moderního přístupu ke knihovnické práci. Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. 2002, s. 195-200.
KAŇKA, J.Koncepce krajského bibliografického systému. Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. 2002, s. 195-201-205.
HRAZDILOVÁ, A. Analytické zpracování v systému T-Series v Krajské moravskoslezské knihovně v Ostravě : Výsledky řešení programového projektu Ministerstva kultury ČR. Čtenář, roč. 54, č. 4, 2002, s. 116-117
IFLA. Dostupný z URL: http://www.ifla.org/
68th IFLA Council and General Konference, August 18-24, 2002. Glasgow. Dostupný z URL: http://www.ifla.org/.
HADDAD, P.GATENBY, P.Providing bibliographic access to archived online resources: the National Library of Australia´s approach. 68th IFLA Council and General Konference, August 18-24, 2002. Glasgow. Dostupný z URL: http://www.ifla.org/, http://www.nla.gov.au/nla/staffpaper/2002/gatenby.html.
DAGERSTEDT, S.: Cataloguing and organizing library workflow - New wals. 68th IFLA Council and General Konference, August 18-24, 2002. Glasgow. Dostupný z URL: http://www.ifla.org/. Pozn.: nepřístupný
SMITH, R. The European Library Project: managing bibliographic standards at the European level. 68th IFLA Council and General Konference, August 18-24, 2002. Glasgow.
CELBOVÁ, L.: Katalogizace elektronických zdrojů : příručka pro katalogizátora. Praha, Národní knihovna České republiky, 20000
EDVARDSEN, JONNY. Newspapers at the National Library of Norway. News from the IFLA Round tabel of Newspapers. 2002, No. 10. Dostupný z URL: http://www.ifla.org/VII/s39/broch/no10.pdf.
SCHWARZ, J: Současný stav a trendy automatické indexace dokumentů. Přehledová studie. 2002. Dostupný z URL: http://full.nkp.cz/
RICHTER, V.Návrh nové "Strategie rozvoje knihoven 2003-2005" Knihovny současnosti 2002. Sborník z 10. konference, konané ve dnech 24.-26.září 2002 v Seči u Chrudimi. 2002.
SVOBODA, M.Knihovny v elektronické záplavě. Automatizace knihovnických procesů . 9. ročník. Liberec.2003. Dostupný z: http://knihovny.cvut.cz/akp2003/.
SKLENÁK, V. Sémantický web. Knihovny v elektronické záplavě. Automatizace knihovnických procesů .9. ročník. Liberec. 2003. Dostupný z: http://knihovny.cvut.cz/akp2003/.
ŽABIČKA, P. OAI-PMH: Protokol pro metadatovou interoperabilitu. Automatizace knihovnických procesů . 9. ročník. Liberec. 2003. Dostupný z: http://knihovny.cvut.cz/akp2003/ .
ANDĚROVÁ, I.. Kooperační systém článkové bibliografie a báze ANL, ANL FULL. Infos 2003: zborník z 32. medzinárodného informatického sympózia, ktoré se konalo v dňoch 7.-10 apríla 2003 v Starej Lesnej. Sest. Alojz Androvič, Judita Kopáčiková. Bratislava, Centrum VTISR 2003. S. 149-161.
KOVAČKA, M. Prvé výsledky a najbližšie perspektivy národného programu retrokonverze a konverze bibliografických databáz a knižničných katalogov Slovenskej republiky. Infos 2003: zborník z 32. medzinárodného informatického sympózia, ktoré se konalo v dňoch 7.-10 apríla 2003 v Starej Lesnej. Sest. Alojz Androvič, Judita Kopáčiková. Bratislava, Centrum VTISR 2003. S. 135-140.
BARTOŠEK, M. Aktuální oblasti výzkumu digitálních knihoven Infos 2003: zborník z 32. medzinárodného informatického sympózia, ktoré se konalo v dňoch 7.-10 apríla 2003 v Starej Lesnej. Sest. Alojz Androvič, Judita Kopáčiková. Bratislava, Centrum VTISR 2003. S. 84-90.
Congress: 69th IFLA General Conference and Council. Access Point Library: Media - Information - Culture.1 - 9 August 2003, Berlin, Germany. Dostupný z: http://www.ifla.org/IV/ifla69/index.htm.
BARTOŠEK, M. Digitální knihovny. Dostupný z: http://www.ics.muni.cz/mba/dl-fi03/dlfi03-1.pdf.
ANDĚROVÁ, I. Problematika novin a World Library and Information Congress : 69th IFLA General Conference and Council. Media - Information - Culture . Ikaros [online]. 2003, č. 11 [cit. 2003-11-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200311005. ISSN 1212-5075.
Ikaros, redakce. Program LI znamenal průlom ve financování informačních zdrojů. Ikaros [online]. 2003, č. 08 [cit. 2003-08-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200307009. ISSN 1212-5075.
SCHWARZ, J. Současný stav a trendy automatické indexace dokumentů :
přehledová studie. Ikaros [online]. 2003, č. 03 [cit. 2003-03-01]. Dostupný z:
http://www.ikaros.cz/Clanek.asp?ID=200303002. ISSN 1212-5075.
Pozn.: Originální verze studie je zveřejněna na adrese http://full.nkp.cz/nkdb/docs/studie/MAIobsah.html, zkrácená a
upravená verze studie byla prezentována na konferenci Znalosti 2003 (viz
Schwarz, J. Současný stav a trendy automatické indexace dokumentů. In Svátek, V.
(ed.). Znalosti 2003 : 2. ročník konference, Ostrava, 19.-21. únor 2003. Sborník
příspěvků. Ostrava : VŠB-Technická univerzita Ostrava, 2003, s. 212-221.
HARTMANOVÁ, D. Knihovna on-line a autorské právo. Národní knihovna : knihovnická revue, 2003, roč. 14, č. 2, s. 100-105. Dostupný též z: http://full.nkp.cz/nkkr/NKKR0302/0302100.html.
BROŽEK, I.; PĚNKAVOVÁ, P.; ŠTĚRBOVÁ, J.; HOREJSKOVÁ, M. Knihovny současnosti 2003. Ikaros [online]. 2003, č. 10 [cit. 2003-10-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200309009. ISSN 1212-5075.
SVOBODA, M. PQNext: Nová verze vyhledávacího prostředí služby ProQuest 5000. Ikaros [online]. 2003, č. 08 [cit. 2003-08-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200308004. ISSN 1212-5075.
CELBOVÁ, L. Automatizace knihovnických procesů podeváté. Ikaros [online]. 2003, č. 06 [cit. 2003-06-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200305005. ISSN 1212-5075.
SVOBODA, M. Zpráva z cesty na seminář ELAG 2003. Ikaros [online]. 2003, č. 08 [cit. 2003-08-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200308001. ISSN 1212-5075.
MACHONSKÁ, J. Cenová politika databázových center. Historie a současnost. Národní knihovna : knihovnická revue, 2002, roč. 13, č. 3, s. 177-195. Dostupné z: http://full.nkp.cz/nkkr/NKKR0302/0302100.html.
BRATKOVÁ, E. Citace odborné literatury jako nástroj rozvoje služeb a integrace digitálních knihoven. Dostupný z: http://platan.vc.cvut.cz/akp/clanky/12.pdf .
Van de SOMPEL, H.- HOCHSTENBACH, P. Reference Linking in a Hybrid Library Environment. Part 1-3. D-Lib Magazine [online]. 2000, vol 5, no. 4, no. 10. Dostupný z: http://www.dlib.org/.
BALÍKOVÁ, M.: Soubor věcných autorit. Předmětová kategorizace pro potřeby konspektu. Knihovny současnosti 2003 11. konference konaná ve dnech 16.-18.září 2003 v Seči u Chrudimi. Dostupný z: jib-info.cuni.cz/dokumenty/sec2003/sec2003_mb.ppt .
PAVLÍK, J. Linkování na relevantní přidané služby v rámci Jednotné informační brány Knihovny současnosti 2003. 11. konference konaná ve dnech 16.-18.září 2003 v Seči u Chrudimi. Dostupný z: http://jib-info.cuni.cz/dokumenty/sec2003/sec2003_sfx.doc .
SKLENÁK, V. Vyhledávací stroje v prostředí Internetu - a co bude dál? Dostupný z: http://platan.vc.cvut.cz/akp2003/sbornik/03_sklenak.pdf.
ANDĚROVÁ, I. Aktuální informace o Kooperačním systému článkové bibliografie SDRUK , 13. zasedání Sekce pro bibliografii. Hradec Králové, 5.-6.5. 2003. Dostupný z: http://full.nkp.cz/, Rubrika Co je nového … .
ANDĚROVÁ, I.Problematika novin a World Library and Information Congress :
69th IFLA General Conference and Council. Media - Information - Culture . Ikaros
[online]. 2003, č. 11 [cit. 2003-11-01].
Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200311005. ISSN
1212-5075.
BULÍNOVÁ, E. Souborné katalogy Ruska, Běloruska, Ukrajiny a pobaltských zemí. Ikaros [online]. 2004, č. 01 [cit. 2004-01-01]. Dostupný z . ISSN 1212-5075">http://www.ikaros.cz/Clanek.asp?ID=200401008>. ISSN 1212-5075.
JEDLIČKOVÁ, P. Tvořivé propojení technické inteligence a zájmu o humanitní disciplíny : Rozhovor s Prof. PhDr. Marií Königovou, CSc. Ikaros [on line]. 2004, č. 01 [cit. 2004-01-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200311018. ISSN 1212-5075.
SKOLKOVÁ, L. OCLC láká prostřednictvím Google nové uživatele do knihoven. Ikaros [online].2003,č.12[cit.2003-12-01]. Dostupný z: http://www.ikaros.cz/Clanek.asp?ID=200312002. ISSN 1212-5075.
Některé globální odkazy
K OpenUrl: Linking to the Appropriate Copy: Report of a DOI-Based
Prototype, Oren Beit-Arie et al., September 2001
Generalizing the OpenURL Framework beyond References to Scholarly
Works: The Bison-Futé Model, Herbert Van de Sompel and Oren Beit-Arie, July
2001
OpenResolver: a Simple OpenURL Resolver, Andy Powell, June
2001
CrossRef Turns One, Amy Brand, May 2001
Open linking for libraries: the OpenURL framework, Jenny
Walker, 2001
TOPIC
Verity
Standardizace
http://wwwold.nkp.cz/(katalogizační politika) JIB
Dokumenty - konspekt
Webarchiv
Statement of
International Cataloguing Principles
Globální pohled na problematiku
M. Svoboda -
Bibliografie
Praktické výsledky projektů prezentované na www
Seriály
(periodika) a analytický popis (články) v České republice, plné texty Propojení
bibliografických záznamů s plnými texty [online]. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=oazp_odd_anal_zprac.htm.
Metodika
popisu článků ve formátu UNIMARC [online]. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=oazp_popis1.htm.
Server
FULL.NKP.CZ . Dostupný z URL: http://full.nkp.cz/.
Báze ANL FULL .Dostupný z URL: http://full.nkp.cz/.
Management Kooperačního systému
článkové bibliografie - MNG KOSABI. Dostupný z URL: http://full.nkp.cz/.
Plné
texty v českých novinách a časopisech - přehled. Dostupný z URL: http://full.nkp.cz/.
Výsledky práce společnosti ANOPRESS IT. Dostupný z URL: http://www.anopress.cz/ .
Seznam seriálů excerpovaných v oddělení analytického zpracování. Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=oazp_Seznam_OAZ.htm.
Knihovny spolupracující v kooperačním systému článkové bibliografie a excerpční základny Dostupný z URL: http://wwwold.nkp.cz/pages/page.php3?page=oazp_kooper_svk.htm.
Báze ANL [online]. Dostupný z URL: http://sigma.nkp.cz/F/5B28NFHIE6HYVM2F3QEFCRA4EG4EVJUHP5RMRRQRQAC9XH94P6-01732?func=file&file_name=find-a&local_base=anl.
Národní knihovna. Knihovnická revue [online]. Dostupný z: http://full.nkp.cz/nkkr/NKKR.html.
JIB Caslin. Dostupný z URL: http://www.jib.cz/.
Zahraniční reference
General information about ANL - Articles in Czech newspapers, magazines and collections of works.Login procedures to ANL [FULL] - Articles published in Czech journals and newspapers (full texts). Gabriel. Dostupný z URL: http://portico.bl.uk/gabriel/index.html
ANL FULL. Dubline Core Metadata Initiative. Dostupný z URL: http://dublincore.org/projects/europe.shtml#denmark.
Tel Digital deposits state of the art review. Marco de Niet, Koninklijke Bibliothek. With contribution form Liesbeth Pskamp, Koninklijke Bibliotheek. 18 December 2001. 0.2 (Second draft version).D1.1/R/Report. DEL/007. Hague, Koninklijke Bibliotheek 2001. 84 p. Dostupný z URL: http://www.europeanlibrary.org/pdf/tel_results_d11_v02.pdf
IFLA-Directory of Serials Content Databases and Current-Awareness Services for Serials Content. [V přípravě]. IFLANET. Dostupný z URL: http://www.ifla.org/I/whatsnew/new2002.htm.
A.2 Současný stav ve světě a v ČR
A.2.1 Obecně
Množství sekundárních i primárních zdrojů dostupných on-line vyžaduje jejich
účelné propojení, na konci informačního procesu by měl být relevantní plný text.
Optimalizovat zpřístupnění plných textů předpokládá vytvoření podmínek k tomuto
propojení jak po stránce standardizační, tak po stránce technické či
technologické, organizační a legislativně právní.
Informace, které jsou
včasné, rychlé, konkrétní přizpůsobené informačním potřebám koncových uživatelů
jsou nezbytné pro vývoj moderní společnosti. Současná informační věda hovoří
umění informaci či znalost vyhledat a použít (vytěžování médií - media mining) a
umět informaci nebo znalost organizovat tak, aby byla využitelná dále.
Záměrem předkládaného projeku je zmapování nejnovějších trendů a na jejich
základě vytvoření základní koncepce pro optimalizaci zpřístupnění plných textů s
ohledem na informační systém v ČR a v jeho rámci na Kooperační systém článkové
bibliografie.
Současným trendem je propojování informačních zdrojů na
internetu. Optimalizace zpřístupnění plných textů spočívá v aplikaci nástrojů,
které toto propojení umožňují a týká se prakticky celého procesu získávání,
zpracování a zpřístupnění plných textů na internetu na základě inteoprerability
všech komponent, které v tomto procesu fungují. Propojují se A&I databáze s
plným textem, citace v plném textu na plný text, z OPACu k časopisu a jeho
obsahu a odtud k plnému textu, některé linky jsou statické pro konkrétní případy
předem budované. Dynamické linky jsou budovány následně, v době potřeby, jsou
pravděpodobnostní. Někdy je vhodné kombinovat tyto dva druhy propojení.
Současným trendem, je extrahování, automatizované zpracování metadat ,
otevřené propojování informací, pojmové vyhledávání v plnotextových databázích a
interoperabilita systémů založených na různých platformách.
Kvalitní zpřístupnění informací o článcích či statích publikovaných novinách, časopisech, sbornících aj. periodicky vydávaných dokumentech je důležité pro oblast státní správy a samosprávy, pro oblast vzdělávání a výzkumu i pro praktickou realizaci výsledků vědy a výzkumu. Nutnost nových modelů zpracování a zpřístupňování bibliografických informací je evidentní.
Projekt je koncepční a částečně realizační (dílčí řešení), úzce souvisí s
programovým projektem týkajícím se Kooperačního systému článkové bibliografie,
dále pak s JIB a projektem Webarchiv.
Koncepce zde navrhnutá včetně
jednotlivých dílčích řešení je realizovaná v projektu Souborná databáze
Kooperačního systému článkové bibliografie - optimalizace integrace a správy
heterogenních dat, proto jsou použity některé materiály ze zpráv k tomuto
projektu. Bez projektu Souborná databáze, by koncepci nešlo realizovat.
A.2. Současný stav v zahraničí
Rozvoj Internetu, elektronického publikování (jeho výhody a nevýhody), typy elektronických dokumentů (primárně elektronické, elektronické verze tištěných dokumentů nebo jejich doplňky) a jejich vlastnosti ovlivňují tradiční metody získávání (volné elektronické dokumenty na Internetu, získání elektronické formy/verzi dokumentu v rámci předplatného od vydavatele, dodavatelské/distribuční firmy, v rámci povinného výtisku), zpracování (automatická nebo automatizovaná indexace/extrakce, metadata Dublin Core), archivaci, vyhledávání a zpřístupňování dokumentů (XHTML, XML, intuitivní vyhledávání a dialogové interaktivní systémy). Objevují se pokusy rozšířit či zkvalitnit obsah elektronické publikace pomocí prostředků, které nabízí Internet. Dochází tak ke kombinaci tradičně katalogizovaných dat s katalogizací vzdálených zdrojů, s dodáváním metadat od autora, vydavatele/nakladatele/distributora i dat získaných na základě automatizovaného sběru. Na druhé straně se mění způsoby informačního chování uživatele při vyhledávání, ve středu zájmu je komunikace člověk - počítač (human-computer interaction). Na základě zpětné vazby relevance (relevance feedback) může uživatel zpřesňovat svůj dotaz a spolupracovat se systémem. Kombinace bibliografických a plnotextových databází představuje efektivní přístup k plnému textu. Vyhledávání s přidanou hodnotou a intelektuální indexace věcná zvyšují možnost získání relevantních informací.
V současné době vznikají nové modely získávání, zpracování a zpřístupňování bibliografických informací v návaznosti na elektronické publikování na základě přehodnocení klasických knihovnických postupů s ohledem na budování digitální knihovny ( interoperabilita jednotlivých komponent z hlediska technického, strukturálního, syntaktického a sémantického). Propojují se různé informace z hlediska formy, druhu a obsahu, strukturované a nestrukturované fulltextové báze, elektronické archívy. Propojují se katalogy knihoven, záznamy s plnými texty dokumentů, "síťové dokumenty", je podporována spolupráce s archívy apod. Zdroje se integrují do informačních bran, portálů, virtuálních, digitálních či elektronických knihoven. Hovoří se o popisu dokumentu v hierarchii jako manifestace díla (čtyřúrovňový model manifestace díla FRBR) - vztahy mezi dílem, jeho vyjádřením, projevem a exemplářem.
Elektronické dokumenty jsou zpřístupňovány prostřednictvím nakladatelství, distributorských firem, informačních institucí či služeb a jejich produktů, dále pak prostřednictvím digitálních knihoven a služeb vznikajících na základě projektů, konzorcií a licencí. Při zpřístupňování elektronických informací se stále více prohlubuje spolupráce mezi státním a soukromým sektorem.
Předpokladem plnohodnotného zpřístupnění plných textů je implementace metadat do plných textů. Tato metadata (DC, Marc) mohou být vytvářena autorem, vydavatelem, distributorem, knihovníkem a zpřístupňována na webu pomocí XML/RDF s definovanou standardní strukturou DTD. Existují iniciativy, které se zabývají konverzemi mezi DC, MARC a XML. DC je určen primárně pro otevřený web, lze ho užít i pro databáze tzv. hlubokého webu. Významný je OAI-PHP (v. 2) protokol - protokol pro metadatovou interoperabilitu, umožňující automatizované získávání metadat a vzájemnou komunikaci archivů, digitálních knihoven, je založený na DC a XML. V současné době se velká pozornost věnuje protokolům pro komunikaci a sdílení dat - Z39.50 a Bath Profile a tzv. otevřenému nebo dynamickému propojováni pomocí tzv. OpenURL.
Jednoznačná indentifikace plných textů je jednou z podmínek zpřístupnění plných textů. K identifikaci služeb, zdrojů a objektů na internetu slouží nestabilní URL (Uniform Resource Locator), PURL (Persistent URL), Uniform Resource Name URN (Uniform Resource Name), DOI (Document Object Identifier), SICI (Seriál Item and Contribution Identifier) aj.
Informační brány a portály usnadňují přístup k heterogenním informačním zdrojům. Předpokladem plnohodnotného zpřístupnění dokumentů je standardizace a cílem je sémantický web.
Trendy, nástroje , metody a projekty týkající se integrace dat a získávání, zpracování a zpřístupnění plných textů (pro definice některých pojmů jsem použila databázi terminologická databáze knihovnictví a informační vědy -- TDKIV)
1.Trendy
Základní trend: kooperace v rámci interoperability systémů na základě spolupracujících komponent v celém procesu získávání, zpracování a zpřístupňování informací, tj. přechod od explicitní pevně svázané kooperace ke kooperaci nezávislé na použitých SW a HW za účelem zajištění pružné integrace dat a jejich zpřístupnění v rámci jednotného interface za využití moderních vyhledávacích metod umožňující interakci uživatele se systémem.
Základní předpoklad - interoperabilita: Interoperabilita je schopnost dynamické spolupráce mezi technicky různorodými a nezávislými komponentami z hlediska syntaktického, strukturálního a sémantického. Interoperabilitu kromě jiných umožňují i zde jmenované nástroje. Různé úrovně interoperability z hlediska použitých prostředků: webové vyhledávače, silné standardy - MARC, Z39.50; metada, jejich sklízení a otevřené standardy; zdroje s metadaty volně zapojené do kooperace - DC, XML, RDF; interoperabilita v oblasti propojování zdrojů např. OpenURL, ERL, dále pak propojení citlivé na kontext uživatele (open context-sensitive linking) - UpenURL a SFX. Významné jsou aktivity v oblasti ontologií (systém konceptů a vztahů mezi nimi).
Syntaktické interoperability se dosáhne vyznačením dat podobným způsobem, takže je možné sdílet data v různých systémech.
Strukturální interoperabilita vyjadřuje strukturu metadat. Strukturální interoperability se dosáhne pomocí datového modelu pro specifikaci sémantických schémat, takže se mohou aplikovat společně (např. RDF)".
Sémantická interoperabilita je "obsahové vyjádření struktury metadat, které dovoluje sémanticky kombinovat datové prvky z různých schémat, slovníků a jiných nástrojů a umožňuje tak vyhledávat informace napříč heterogenními distribuovanými databázemi, zejména v prostředí internetu zadáním jediného dotazu. Pomocí sémantické interoperability jsou řešeny např. případy, kdy jednotlivé zdroje používají různé termíny pro popis téhož pojmu (např. autor, tvůrce a skladatel) nebo naopak, používají stejné termíny pro různé pojmy. Sémantické interoperability lze dosáhnout užíváním standardů popisu obsahu zdrojů (např. AACR nebo Dublin Core, FRBR)."
Ontologie - metoda získávání znalostí. Dílčí ontologie souvisí s
konceptualizací jednotlivých oblastí.
Ontologie, resp. tzv. topikové mapy
umožňují členit textové univerzum z hlediska sémantiky. Kategorie je třeba
propojit s koncepty.
Na základě interoperability mohou vznikat snadněji elektronické archívy, souborné katalogy virtuální i reálné, brány a portály.
Cílem je propojování informací, distribuované vyhledávání, relevantní (pertinentní) informace pro uživatele a sémantický web. Tzv. sémantický web předpokládá postupnou transformaci současného WWW srozumitelného pro lidi na WWW srozumitelného pro počítače (znalosti označené značkovacími jazyky nebo extrahované z textu).
2. Některé nástroje, metody, projekty odpovídající současným trendům majícím vliv na pří zpřístupňování plných textů s ohledem na interoperibilitu
Zpřístupnění plných textů z hlediska organizace
Hybridní knihovna
Knihovna integrující klasickou knihovnu
představovanou především tištěnými dokumenty a digitální knihovnu.
Digitální knihovna je "integrovaný systém zahrnující soubor elektronických informačních zdrojů a služeb umožňující získávání, zpracovávání, vyhledávání a využívání informací v tomto systému uložených. Umožňuje jednotný přístup k digitálním anebo digitalizovaným dokumentům, případně i k sekundárním informacím o tištěných primárních zdrojích, uložených ve fondu knihovny" i mimo fond knihovny.
Elektronický archív
"Organizovaná sbírka digitálních dokumentů
shromážděná za účelem jejich dlouhodobého uchování. Může se jednat o
digitalizované dokumenty, tj. tištěné druhy dokumentů převedených do digitální
podoby, nebo o dokumenty vytvořené již jako digitální."
Reálný souborný katalog
Souborný katalog ve formě fyzicky
existující databáze, do které jsou dodávány záznamy dokumentů jednotlivých
účastnických knihoven.
Virtuální souborný katalog
"Technologie propojení nezávislých
knihovních katalogů pomocí jednotného uživatelského rozhraní, které umožňuje
paralelní prohledávání jednotlivých katalogů a vytváří virtuální (reálně
neexistující) souborný katalog. Základním předpokladem funkce virtuálního
souborného katalogu je standardní vyhledávací protokol, jenž podporuje formulaci
rešeršního dotazu a zpřístupnění záznamů (např. komunikační protokol
Z39.50)."
Informační brána
"Služba v síťovém prostředí určená pro
zprostředkování přístupu k vybraným online informačním zdrojům určitého
oborového nebo tematického zaměření. Zpřístupňované informační zdroje
procházejí procesem intelektuálního nebo automatického výběru a zpracování na
základě definovaných formálních a kvalitativních kritérií. Součástí předmětové
brány je obvykle klasifikační systém členící informační zdroje podle
oborů".
Informační brány řeší přístup k různým zdrojům z jednotného
prostředí. Nejpoužívanějším standardem pro tvorbu metadat je Dublin Core
(DC). Jejich fungování závisí na existenci pokud možno homogenního nástroje pro
věcnou indexaci harmonizací řízených slovníků a tezaurů a hledají se cesty k
řešení vícejazyčnosti. Jednou z řešených metod pro zpřístupnění elektronických
informačních zdrojů je metoda konspektu, předmětová kategorizace pro
popis informačních zdrojů. Spočívá hierarchickém uspořádání předmětových
kategorií, na nejvyšší úrovni není propojena se systematickou klasifikací. Cílem
je jednotný tematicky strukturovaný popis heterogenních informačních zdrojů pro
potřeby koordinovaného budování knihovních sbírek a knihovních fondů a pro
tvorbu nástroje určeného ke zpřístupnění kvalitních (zhodnocených) heterogenních
informačních zdrojů v síťovém prostředí, tj. tematických bran. Slouží k tomu
údaj o předmětové kategorii spolu s vybraným znakem MDT. Pro mezinárodní
srozumitelnost je potřebná konkordance MDT a DDC.
Portál
Webové sídlo, které poskytuje širokou škálu služeb a
informací, často s možností jejich přizpůsobení uživateli podle osobních potřeb
a zájmů.
Specializovaný portál zpřístupňující informační zdroje
zaměřené na určitou cílovou skupinu uživatelů, která může být vymezena např.
geograficky nebo tematicky.
Zpřístupnění plných textů z hlediska standardů a nástrojů (včetně technologických) - předpoklady optimalizace zpřístupnění plných textů a propojování
Pravidla popisu - jejich zjednodušení a zefektivnění, formáty
Jmenný popis
Na mezinárodní úrovni se mění tradiční pojetí seriálů, které bude mít vliv i
na naší katalogizační praxi v této oblasti. Termín seriál je
revidován. V současné době již existuje revidovaný standard International
Standard Bibliographic Description for Serial and other Continuing Resources
ISBD (CR). Revize je ovlivněna novou kategorií tzv. pokračujících
zdrojů (bibliografický zdroj, který je vydáván v čase s předem neurčenou
dobou ukončení, zahrnuje integrující zdroje a seriály, povaha pokračujících
zdrojů je dynamická, pokračující a měnitelná.). Integrující zdroje jsou
zdroje, které jsou aktualizovány a tyto aktualizace nemohou existovat
samostatně. Dochází k harmonizaci Angloamerických pravidel AACR2R, mezinárodního
bibliografického popisu ISBD a mezinárodního registračního systému mezinárodního
čísla seriálových publikací ISSN. Do kategorie pokračujících zdrojů patří též
ukončené pokračující zdroje - vycházejí po částech, periodicky a jsou číslovány,
ale jejich trvání je ohraničeno, dále reprinty seriálů. Pro praktické potřeby je
navržena definice seriálů: seriál je pokračující zdroj, který je vydáván
po oddělených částech, obvykle je číslován, nemá předem určenou dobu ukončení.
Definice zahrnuje časopisy, magazíny, elektronické časopisy, pokračující
adresáře, roční zprávy, noviny a monografické edice (těmito kategoriemi se
zabývá kapitola 12 AACR2R). Pro popis elektronických zdrojů je určen
standard ISBD (ER) a kapitola 9 AACR2R. Studie Functional Requirements
for Bibliographic records (FRBR) - viz dále. Studie uvádí čtyřúrovňový
popis, orientuje se na obsah dokumentu, nikoli na nosič, umožňuje integrovat
elektronické dokumenty mezi dokumenty tradiční. Účelem studie je definovat
funkce bibliografického záznamu určeného pro různé typy dokumentů, způsoby
využití, pro různé uživatelské potřeby. V současné době probíhají aktivity,
které zkoumají použitelnost pravidel AACR2 i formátu MARC vzhledem k FRBR a
aktivity v oblasti přípravy mezinárodních katalogizačních pravidel (viz
dále).
V oblasti věcného zpracování: zjednodušení syntaxe LCSH za
současného zachování lexiky, věcná kategorizace informací do určitého počtu
skupin na několika úrovních (např. metoda konspektu), důraz na autority a jejich
mezinárodní srozumitelnost (projekty projekt MACS a LEAF).
Metadata jsou "strukturovaná data, která nesou informace o primárních datech. Pojem metadat je používán především v souvislosti s elektronickými zdroji a vztahuje se k datům v nejširším smyslu slova (datové soubory, textové informace, obrazové informace, hudba aj.). Funkce metadat je popisná, selekční a archivační. V souvislosti s těmito funkcemi se rozlišují metadata pro účely popisu, správy, právních nároků, technické funkčnosti, užití a archivace. Údaje se obvykle vkládají přímo do zdroje (umísťují se např. v záhlaví dokumentu HTML)". Mohou existovat i odděleně.
Dublin Core (DC) je standardizované metadatové schéma pro popis informačních zdrojů zejména na internetu. Dublin Core je tvořen souborem patnácti základních prvků (jednoduchý Dublin Core), které lze specifikovat kvalifikátorem prvku a hodnoty (kvalifikovaný Dublin Core). Dublin Core nepředepisuje závaznou syntaxi (jedná se o sémantický standard), je základem dalších metadatových standardů.
Každý prvek je volitelný a opakovatelný, nezáleží na jejich pořadí. Důležitou podmínkou interoperability je používání hodnot prvku z dohodnutých souborů autorit.
Vazba mezi metadatovým záznamem a zdrojem, resp. plným textem, který popisují, může být dvojí: metadatový záznam je uložen samostatně a odděleně od zdroje nebo metadata jsou vnořena (embedded) přímo do samotného zdroje (pomocí značek u dokumentů v jazyce SGML, HTML aj.)
Z DC vychází např. metadatový standard OAI (Open Archives Initiative) primárně vyvinutý pro vědecké a akademické komunity. Projekty, které využívají DC, je možno najít na adrese http://dublincore.org/projects. V budoucnu by mělo dojít k možnosti konverze mezi národními metadatovými záznamy.
(DC se v České republice zabývají pracovníci ÚVT MU, materiály týkající se DC jsou prezentovány na http://www.ics.muni.cz/dublin_core/index.html , projekt Webarchiv, JIB, projekty týkající se článkových informací - viz dále).
Předpokládaný vývoj Dublin Core (cit. Bartošek, 1999)
- vývoj a zpřesňování základního souboru nekvalifikovaného DC;
- rozvoj kvalifikovaného DC;
- vývoj nových nástrojů pro vytváření a správu metadat a podpora aplikačních projektů využívajících DC;
- postupná formální standardizace (od jednodušších komponent ke složitějším) nejen v rámci internetové komunity (IETF), ale i národních a mezinárodních standardizačních institucí (NISO, ISO);
- koordinace vývoje Dublinského jádra s rozvojem jiných metadatových projektů a standardů; RDF - Resource Description Framework - rozšířený konceptuální model pro vyjádření metadat na Webu umožňující kombinovat různá metadatová schémata (vyvíjen konsorciem W3C) a projekt INDECS - Interoperability of Data in E-commerce Systems - zaměřený na metadata pro potřeby správy autorských a vlastnických práv
RDF (Resource Description Framework)
"Obecný rámec pro popis
jakéhokoli elektronického zdroje, resp. webové stránky a jejího obsahu, tedy pro
vyjádření sémantiky a pro podporu sémantického webu. Popisná metadata mohou
zahrnovat údaje o autorovi zdroje, datu vytvoření nebo aktualizace, organizaci
stránek (sitemap), klíčová slova, předmětové kategorie aj. Jazyk RDF
poskytuje robustní flexibilní architekturu pro zpracování metadat na
internetu; umožňuje komukoli definovat a používat metadatové schéma, které
slouží nejlépe jeho potřebám, a současně umožňuje interoperabilní výměnu
metadat. RDF je aplikací formátu XML a je vyvíjen konsorciem W3C (World
Wide Web)."
Poskytuje základ pro popis v různých aplikačních doménách. Jako
modelovací jazyk používá entity, atributy, vztahy.
XML (eXtensible Markup Language) Jazyk XML je, podobně jako jazyk
HTML, prostředek sloužící k zapsání strukturovaného textu , zvláště pak
textu určeného k šíření v prostoru www. XML odděluje popis struktury dat od
jejich prezentace (pomocí tzv. style sheetů). To umožňuje snadnou konverzi do
jiných formátů, možnost prezentace dat různými způsoby (HTML, postcript, UNIMARC
apod. textový formát). Každý dokument má definovanou svoji strukturu
prostřednictvím tzv. DTD (Document Type Definition). Velký potenciál XML
se skrývá v novém způsobu odkazování (oběma směry, na více dokumentů najednou či
dokonce v rámci hierarchické struktury) pomocí speciálních jazyků XLink,
XPointer a XPath. Totéž lze říci o stylovém jazyku XSL, který doplňuje a
nahrazuje tzv. kaskádové styly (CSS).
V současnosti probíhají aktivity v oblasti mapování
formátu DC do MARC a opačně a převodu do XML.
XML metajazyk umožňující definovat značkovací tagy podle konkrétních
požadavků, definice povolených značek tvoří DTD nebo XML schéma.Nezabývá se
sémantikou, ale strukturou..RDF určuje význam na základě vztahu objekt, atribut,
hodnota.
RDF schéma (RDFS) je nadstavba umožňující vytvářet RDF struktury na
základě defince tříd a podtříd, vlastností a podvlastností, definičního oboru.
RDF a RDFS představují mechnismus reprezentace znalostí pro web zdroje.RDFS má
nedostatečný potenciál pro vytváření ontologií. Ty odtsraňuje např. jazyk
DAM+OIL.
Vyhledávání informací a sématický web
Vyhledávací stroje a roboty
vytvářejí z plných textů index, zvyšují úplnost vyhledávání na úkor
přesnosti.Vyhledávací služby za asisence člověka přiřazují dokumenty k
jednotivým kategoriím - vysoká přesnost, nízká úplnost.
Ontologie a sémantický web
Zahrnutí sémantiky do vyhledávání, práce s
ontologiemi vyžaduje vyžaduje nové přístupy při zpracování
informací.
Na základě sémantických značek bude možné realizovat různé typy
vyhledávání : IR - identifikace relevantních dokumentů, jednoduché a komplexní
odpovědi na otázky odpovědi na otázky (Question answering Q and A) - různé
techniky odvozování a usuzování, techniky extrakce a sumarizace
informací.
Sémantický web - přiřazení datům přesný význam. Ontologie - metoda
získávání znalostí. Dílčí ontologie souvisí s konceptualizací jednotlivých
oblastí.
Ontologie je základní technologie sémantického webu, tezaurus se nerovná ontologii.Vztahy v tezauru jsou BT, NT, UF, RT. Ontologie užívá množství strukturních a konceptuálních vztahů třída, podtřída, instance, vztahů k času, podle typu jazyka - tj. strukturní a konceptuální vztahy.
OAI-PHP (v. 2) je protokol pro metadatovou inteoperabilitu, umožňuje automatizované získávání metadat a vzájemnou komunikaci archivů, digitálních knihoven - otevřené technické řešení., dostupnost SW komponent. Založen na použití jednozačných idnetifikátorů, metadatový standard je nekvalifikovaný DC, komunikace přes HTTP a využití formátu XML. Protokol aplikují souborné databáze, archivy volně dostupných vědeckých prací (arXiv.org) a výzkumných institucí (CERN), knihovny (Library of Congress). Např. i služba DP9 - umožní indexaci metadat webovými roboty.funkce pro indexaci fulltextů. Další aplikací je projekt Open Citation - automatická tvorba citačních resjtříků. Protokol vyvinit primárně pro potřeby akademické komunity pro zvěřejnění informací. Možno využít při importech d souborných katalogů. Lze použít na bibliografické databáze i souborné katalogy díky schématu MARCXML zveřejněném Library of Congress.
Vyhledávání informací a propojování informací - propojování informačních zdrojů - standardní statické a dynamické propojovací rámce, distribuované vyhledávání
Dnešní vyhledávací stroje na www - velké množství nestrukturovaných dat, obvykle booleovský model vyhledávání - dvě možnosti: podle vztahu mezi dokumentem a dotazem (relevance se počítá podle četnosti slov, polohy, blízkosti; postavení dokumentu v síti). Dále se uživají principy katalogové (vyhledávání podle kategorií) a metavyhledávací. Do dokumentů se vládají matatagy, nejčastěji meta content, keyword, description. Zlepšení nabízí více strukturovat data.Nové metody: shlukování do ad hoc kategoríí, podle podobnosti (odkaz similar pages), služba ResearchIndex provádí analýzu citačních odkazů. Vyhledávání na www se bude vyvíjet - automatická kategorizace, sumarizace extrakce, sémanický web.
V posledních letech nastal rozvoj technologií podporujících automatické a
dynamické propojování informačních zdrojů (Technologie "SFX" Special Effects
vyvinuté na Gentské univerzitě a Národní laboratoři v Los Alamos).
Aktuální
je též např. propojování na základě citací - ISI buduje
SCI (Science citation Index). Projekty založené na propojování archivů na
základě citací - LANL
(propojování na základě přidělovaného identifikátoru a formátu HyperTeX, Los
Alamos National Laboratory) a projekt OpCit (The Open Citation Project).
Iniciativa v oblastí
propojování OAI (The
Open Archive Initiative) navazující na The Open Journal
Project a CoRR.
Základ propojení by měl být uložen již v samém počátků vzniku bibliografických záznamů, jejich katalogizace jednodušší a efektivnější. - FRBR Functional Requirements for Bibliographic Records - relace mezi Dílem, Vyjádřením díla, Provedením díla, a Exemplářem díla (Work, Expression, Manifestation, Item - též český překlad). V současné době probíhají aktivity tímto směrem v oblasti katalogizace - Ustanovení mezinárodních zásad katalogizace (setkání IFLA, Německo 2003).
Druhy propojování (aplikované v komerčních a nekomerčních aktivitách) : propojovat je možno uzavřeně (closed linking), otevřeně (open linking) staticky (static linking), dynamicky (dynamic linking).
Propojování uzavřené - systém má pevné propojovací vazby ( obsahuje nemodifikovatelné vazební informace. V systémech s uzavřeným propojováním tedy nemůže knihovna propojovací vazby měnit, je zcela závislá na producentovi databází
Propojování statické (omezené na určitou autoritu a stabilní umístění propojovaných zdrojů). Předpokládá rozsáhlý sortiment partnerských vztahů. Propojení mezi entitami dáno předem, je dáno a priori. V rámci daného rámce je spolehlivé za předpokladu existence stabilních identifikátorů, na základě kterých je spojení možné přes bázi, ve které jsou umístěny. Jde o centralizovaný koncept, tj. - linky jsou předem zpracovány a uloženy v konkrétní databázi statických linků - v centralizované databázi. Typem linku je statická URL (nestabilní - časté přesuny či úplné odstranění zdrojů na internetu, identifikuje lokaci, ne obsah), PURL (persistentní URL, umístěná na resolveru, který přesměruje poždavek na konkrétní URL na síti, nutno aktualizovat databázi při změně URL, centrální resolver http://purl.oclc.org/), URN (stabilní, jednoznačná, nezávislá na lokaci,založená na resolučním mechanismu automaticky generovaná, plagin na http://urn.issn.org/) a PURN (persistentní URN), SICI (stabilní, automaticky generované) v konntrolovaném systému. Tento typ propojení je realizován např. v projektech IOP, BioMednet, Ovid a mnoha dalších např. v Los Alamos Library Without Walls nebo v Bielefeldu.
Statické propojování funguje na principu : výchozí zdroj, hyperextové propojení, cílový zdroj.
K identifikaci, propojení a zpřístupnění elektronických objektů, resp. plných textů na internetu tedy slouží: URL, PURL, URN a DOI, SICI a klasické identifikátory jako je ISSN, ISBN. Některé z nich mohou být součástí OpenURL.
Identifikátory
URL (Uniform Systém Locator) - "standardizovaný formát lokalizace zdrojů na internetu. Nejznámější a nejrozšířenější typ URI, nemá ovšem funkci trvalého identifikátoru. URL slouží pro různé typy služeb internetu (HTTP, FTP, Telnet, Gopher atd.). Specifikuje jméno a typ zdroje, hostitelský počítač, adresář, kde lze zdroj nalézt. a přenosový protokol potřebný pro použití zdroje. Tentýž zdroj může být prezentován na internetu na více adresách a přístupný pod různými protokoly."
Př. struktury http://server/adr1/adr2/souborPURL (Persistent URL) - "standardizovaný způsob lokalizace zdrojů na internetu; funkčně se jedná o URL. Identifikátor PURL vznikl jako mezikrok pro zajištění stálého přístupu k síťovým zdrojům do doby plné funkčnosti URN s tím, že je zajištěna kompatibilita PURL a URN. Zásadní rozdíl vůči URN spočívá v tom, že PURL odkazuje na zprostředkující službu (službu typu resolver), která zjistí aktuální adresu URL a zašle ji klientovi (místo přímého odkazu na zdroj)".
Př. struktury http://resolver/adr1/adr2/souborURN - "je složené jméno, které se skládá ze jména identifikační autority a identifikátoru objektu přiřazeného touto autoritou. Specifický obsah identifikátoru může být strukturovaný a srozumitelný i pro uživatele, pokud zná pravidla přiřazování identifikátoru v rámci dané identifikační autority". Aplikace bibliografických identifikátorů ve formě jmenných prostorů (ISSN, SICI, ISBN, NBN),
Př. struktury urn: <NID> ":" <NSS>
URN:NBN:cz-nkMF20030303X00003 - urn generované v lince poloautomatické indexace TTDE pro bázi ANL FULL
URN:NBN:cz-nk20031546 - urn generované generátorem v rámci projektu Webarchiv
SICI (Serial Item and Contribution Identifier) - "jednoznačný identifikátor určený pro tištěné a elektronické seriály, který je definován v americké normě ANSI/NISO Z39.56 revidované v roce 1996. Používá se hlavně pro označování článků publikovaných v časopisech a částí ze sborníků. Je založen na standardu ISSN. Identifikuje analytické části seriálů bez ohledu na nosič (papír, mikrofiš, elektronický nosič)".
Norma ANSI/NISO Z39.56 (1991, revize 1996), SICI generátor je dostupný na adrese http://www.ep.cs.nott.ac.uk/~sgp/sicisend.html .
Př:: 1210-1168(20030303)14:52[A/1, A/6:MF20030303X00003]3.0.CO;2-A - SICI generované v lince poloautomatické indexace TTDE pro bázi ANL FULL
DOI - " prostředek pro trvalou identifikaci a propojení dokumentů (objektů), na které se vztahuje intelektuálního vlastnictví. Identifikuje především objekt samotný, nikoliv jeho umístění na síti. Vzhledem k tomu, že se vztahuje k obsahu dokumentu, nikoliv k jeho formě, je DOI údaj shodný pro dokumenty zpřístupňované současně v různých formátech (např. PDF, HTML apod.). Liší se rovněž od dalších běžně používaných identifikátorů, jako jsou např. ISBN, ISRC apod., neboť je navázán na určité služby a sám funguje na síti jako prostředek, jehož cílem je poskytovat uživateli určitou službu (např. lokalizovat dokument). Ve spojení se zprostředkující službou (http://dx.doi.org/10.1007/s00203-002-0481-8) přesměruje prohlížeč na dokument nalézající se na síti"
Př.: 10.1007/s00203-002-0481-8 (článek z časopisu nakladatelství Springer)
The Digital Object Identifier (DOI) je systém pro výměnu intelektuálního vlastnictví na
Internetu. Umožňuje kontakt uživatele s autorem, jemuž zaručuje respektování
jeho autorských práv. Je s ní spojen i systém poplatků. DOI se uvádí u článku a
je přidělen před publikováním. Pro účast v systému DOI je nutné obdržet DOI
prefixy, vybrat číselné schéma, definovat metadata pro přípravu DOI,
zaregistrovat DOI v registrační agentuře. DOI je nástroj k ošetření autorského
práva na internetu.
Přesměrování na server vlastníka, který rozhoduje co a za
jakých podmínek zpřístupněno
Využití: komerční poskytování informačních služeb - elektronické verze odborných časopisů (Academic Press, Blackwell Science, Elsevier Science, Institute for Scientific Information, John Wiley & Sons, Springer Verlag aj.) a elektronické knihy
Př. struktury http://dx.doi.org/10.naklID/sufix Př. http://dx.doi.org/10.1007/s00203-002-0481-8
Propojování otevřené - systém nemá pevné propojovací vazby.
Dynamické propojování - je vhodné kdy nejsou všechna data pod kontorlou autority a je nutné tvoření linků za pochodu ("on the fly") pro existující informační entitu. Dynamické propojení je možné např. prostřednictím OpenUrl. Propojení přes OpenUrl je na principu "just in time", kdy jsou linky realizovány na základě potřeby a je pravděpodobnostní. OpenURL - propojení nezávislé na povaze zdroje propojení a poloze systému. Je to de facto NISO standard pro kódování metadat o zdroji do jeho URL adresy. OpenURL je tedy definovaným formátem URL. Byla vydána The OpenURL Framework for Context-Sensitive Services určená nejen pro akademické prostředí i mimo něj.
Rozšířený model pro OpenURl ( Herbert Van de Sompel, Oren Beit-Arie, 2001)
| OpenURL framework | Bison-Futé model |
| Web-based scholarly information environment | Web in general |
| referenced scholarly
work citation to a scholarly work |
referent citation to a referent |
| hook for citation to scholarly work = OpenURL | hook for citation to referent = ContextObject : |
| * standardized reference to a work | * descriptor of a referent |
| * standardized reference to contextual
elements * hook turned into link = OpenURL |
* descriptors of contextual
entities hook turned into link = OpenResolutionLink |
| service component extended services; reference links the referenced scholarly work; the service component which is the target of the OpenURL; the information service providing the OpenURL |
resolver services entities |
| Table 1: A comparison between the terms used in the OpenURL framework and the Bison-Futé model. |
Dynamické propojení: výchozí zdroj, servisní služba (zde je registrován uživatel), cílový zdroj.
V současné době OpenURL podporují některé informační a knihovnické systémy: Ex Libris Aleph, EOSi Tinlib/T Series, Innovative Innopac, Endavour Voyager, Sirsi Unicorn, Proquest, ISI Web Of Science, EBSCO EBSCOhost, Elsevier Science Direct, Ovid Bibliographic database, SilverPlatter ERL-WebSPIRS, HW Wilson WilsonWeb, CABI Online Abstracts, ... .
OpenURL a SFX
SFX (Special Effects) je technologie založená na OpenURL. Je založena na oddělení popisu zdroje od služeb, které jsou poskytovány. Mezi popisem zdroje a službami stojí tzv. servisní služba (linking service) která propojuje metadata obsazená ve výchozím zdroji, které našel uživatel s vhodným cílovým zdrojem pro uživatele na základe jeho registrace u této servisní služby. Zaručuje tzv. propojení citlivé na kontext (context sensitive linking). Pro připojení informačního či knihovního systému k SFX je nutné, aby systém podporoval OpenURL. Umožňuje poskytovat služby s přidanou hodnotou podle kontextu uživatele (dodání plného textu, abstraktu nebo obsahu, objednávku MVS, zobrazení recenzí, odkazy na informace o jiných zdrojích aj.)
SFX koncept tedy nepracuje s pevnými linky, ale s just-in-time přístupem k dynamickému propojování. Typickými prvky propojení pro články v URL je ISSN, sv, č., rok. Nynější koncept SFX navazuje na experimenty SFX@ Ghent & SFX@ LANL v r. 1999 a je aplikován firmou Exlibris v Metalibu.
Protokol Z39.50 a Bath profil
Bath profil je mezinárodní specifikace Z39.50 pro knihovní systémy a hledání
zdrojů. Aplikace tohoto profilu v ČR je Návrh českého národního profilu Z39.50,
verze 2,, listopad 2002. Profil byl vypracován skupinou ZIG-CZ.
Z39.50 je protokol
pro získávání dat z informačních systémů s použitím Z39.50 klient a Z39.50
server. Umožňuje mezinárodní, nadnárodní a národní vyhledávání a získávání dat
mezi knihovními systémy, soubornými katalogy aj. informačními zdroji.
Specifikuje 4 funkční oblasti (vyhledávání a získávání záznamů bibliografických
a autoritních, exemplářů a záznamů, mezioborové vyhledávání). Mohou být
specifikovány i jiné oblasti (ukládání záznamů a dodávání dokumentů aj.)
Integrace strukturovaných a nestrukturovaných bází dat, inteligentní
vyhledávací systémy, management znalostí, poloautomatické zpracování textu a
extrakce dat, expertní systémy, znalostní systémy
Problematika
získávání, zpracování, zpřístupňování a využívání znalostí je velmi
aktuální v oblasti výzkumu informačních technologií. Významný zdroj znalostí
jsou relační databáze. Dále jsou významné techniky tvorby bází
formalizovaných znalostí na základě spolupráce znalostního inženýra s lidským
expertem. Dalším zdrojem znalostí jsou (vedle databází a expertů) textové
dokumenty. Jejich indexace a vyhledávání je založeno na statistických
a lingvistických charakteristikách (extrakci informací z volného textu).
Systémy využívající formalizované znalostní báze směřují k aplikacím složeným ze
samostatných komponent - agentů - s vlastním mechanismem řízení a
založené na možnosti sdílet a znovu používat znalosti založené na
syntaktické a sémantické standardizaci (značkovací jazyky a znalostní ontologie
tj. konceptualizace určité oblasti). Hlavním cílem těchto technologií je
zdokonalení znalostního managementu v institucích, firmách V důsledku je
efektivní vazba tzv. knowledge managementu na rozhodovací a plánovací procesy.
Mezi renomované znalostní systémy patří systém TOPIC (concept based system) a jeho nová verze Portal One, resp. K2 americké firmy Verity. Informace o systému a reference jsou na adrese společnosti TOVEK. Dalším z těchto systémů je systém Convera Retrieval Ware společnosti Excalibur Technologies. Informace o systému jsou na adrese společnosti INCAD. Předností TOPICu je především pojmové vyhledávání a vysoké interaktivní schopnosti, předností Convery vysoká tolerance chyb při vyhledávání bez ohledu na chyby. Oba systémy umožňují fuzzy vyhledávání.
Pro dnešní dobu je charakteristický trend propojování technologií zpřístupňujících strukturovaná data (relační databáze) s fulltextovými databázemi s nástroji podporujícími zpřístupnění semistrukturovaných dat.
Vyhledávání (cit. Červený, 1999)
Pro vyhledávání je charakteristický nepoměr mezi úplností a přesností vyhledávání. Úplností vyhledávání rozumíme kvantitativní údaj udávající poměr vyhledaných relevantních a všech vyhledaných textů. Přesností vyhledávání rozumíme poměr vyhledaných relevantních a všech relevantních textů. Ideálně je hodnota koeficientu úplnosti i přesnosti rovna 1.
Inteligence informačních systémů je schopnost nalézt shodné modely i v případě textů s vysokým počtem rozdílných prvků a naopak eliminovat texty zdánlivě shodné, obsahující vysoké procento pouze formálně, nikoliv obsahově shodných prvků. Inteligentní systémy využívající poznatky z lingvistiky či kognitivní vědy.
Interaktivní pojetí vyhledávání
Uživatel systému prohlíží seznam vyhledaných záznamů (často i s plnými texty dokumentů) a jednoduše označuje relevantní záznamy. Z relevantních záznamů pak systém automaticky vybere podstatné výrazy, jimiž upraví původní dotaz. Na základě upraveného dotazu systém vyhledá více relevantních záznamů. "dotaz příkladem" (anglicky query-by-example, more like this, find similar či similar pages) fungují na stejném principu. Nový dotaz je však vytvořen pouze na základě jediného vybraného dokumentu.
Koncový uživatel nemusí znát vyhledávací metody a strategie, daný vyhledávací systém, uspořádání sbírky či strukturu záznamů. Aplikace interaktivních technik (re)formulace dotazu tak představuje poměrně jednoduchý způsob, jak nezkušeným uživatelům usnadnit vyhledávání.
Teoretický výzkum interaktivního vyhledávání se soustředí většinou na možnosti zjišťování informací o kognitivním stavu uživatele a jejich použití při konstrukci dotazu. Objevují se však pokusy přímo kognitivní stav uživatelů ovlivňovat. Oblast interaktivního vyhledávání informací je interdisciplinární povahy.
Vyhledávací systémy 3. generace
1. rozkladu pojmu na podpojmy , 2. vážení jednotlivých podpojmů (větví pojmového stromu), 3. neostrého vyhodnocování dotazů
Dotaz v systému 3. generace reprezentuje pojem, respektive ideu vyhledávaného tématu. Jádrem dotazu je stromová hierarchická struktura, která rozkládá hledané téma na podtémata a přiřazuje jednotlivým částem váhy, které vyjadřují do jaké míry příslušné podtéma přispívá k celkovému určení tématu. Systém je pak schopen vypočítat míru relevance (nejčastěji udávanou v % nebo hodnotou v intervalu 0,1), podle které řadí vyhledané dokumenty.
Systém TOPIC eliminuje jeden z nedostatků booleovských vyhledávacích systémů, kterým je přílišná ostrost operátoru AND, jenž nevyhledá dokument, pokud neobsahuje všechna slova tímto operátorem spojená, zavedením operátoru ACCRUE.
Je zřejmé, že je to práce pro specialistu, srovnatelná s tvorbou expertních systémů, neboť dobře nadefinovaná báze topiků představuje vlastně bázi znalostí. Existují funkční systémy na automatizované třídění přicházejících dokumentů, např. agenturního zpravodajství. Dokumenty přicházejí do systému, kde jsou automaticky podrobeny selekci pomocí dobře nadefinovaných topiků (politika, ekonomika apod.).
Klíčovým aspektem úspěšnosti podobného plnotextového systému je vlastní vyvážená definice topiků. Je zřejmé, že je to práce pro specialistu, srovnatelná s tvorbou expertních systémů, neboť dobře nadefinovaná báze topiků představuje vlastně bázi znalostí.
Z hlediska databáze plných textů je z moderní lingvistiky velice zajímavý směr, který se nazývá "textová lingvistika". Jedná se o lingvistickou disciplínu, která považuje za základní jednotku jazyka text. Na vývoji moderní lingvistiky je zajímavé, jak se postupně přenáší zájem jazykovědců ke zkoumání stále větších celků, od hlásek, přes věty až k celým textům (další pravděpodobný krok bude zřejmě od textu k hypertextu). Textová lingvistika již definuje některé pojmy sloužící k popisu textu jako celku. Některé z nich (Makrostruktura, Témata) nápadně korespondují s definicí topiku v systému TOPIC. Dalším směrem ve vývoji těchto systémů je aplikace umělé inteligence, zejména pak systému na porozumění přirozenému jazyku. Informační systém, který by byl založen na tomto principu, by nepotřeboval selekční jazyk a vyhledávání dokumentů by probíhalo dotazováním se systému v přirozeném jazyce.
Poloautomatická indexace textu ( cit. J. Schwarz, 2002)
Většina současných systémů (vč. komerčních) určených pro automatickou indexaci či poloautomatickou indexaci (machine-aided indexing) (vč. komerčních) nepracuje plně automaticky, nýbrž funguje jako automatizovaná podpora intelektuální indexace.
V současnosti je výzkum a vývoj systémů automatické indexace ve fázi, kdy nelze hovořit o plně automatické indexaci. Technologie automatické indexace jsou většinou implementovány jako hybridní systémy, ve kterých se uplatňuje automatická indexace coby automatizovaná podpora intelektuální činnosti indexátora.
Automatická indexace patří do širší oblasti automatizovaného (strojového)
zpracování textu (text processing), resp. obecně zpracování přirozeného jazyka
(natural language processing). Přestože se podařilo vyvinout řadu funkčních
systémů pro automatickou indexaci, více než čtyřicetiletá snaha zatím nevedla k
vývoji systémů, které by byly plně funkční z hlediska ideálních nároků na úplnou
automatizaci procesu indexace a na univerzálnost těchto systémů (většina v
současnosti fungujících systémů je specificky oborově zaměřená). Intelektuální
indexace přináší ve srovnání s řadou automatických procedur (vč. např.
latentního sémantického indexování) ještě stále lepší výsledky. Systémy
automatické indexace jsou také účinné pouze částečně proto, že doposud nebyly
dostatečně prozkoumány a podrobně popsány všechny intelektuální procesy, které
probíhají při indexaci.
Na druhou stranu je potřeba uvést, že řada
technologií, jejichž účinnost byla v předchozích letech potvrzena výzkumem a
řadou studií, je v současnosti implementována ve formě expertních systémů nebo
systémů pracujících na základě umělé inteligence.
Obecně lze konstatovat, že systémy automatické indexace vyvíjejí oborově zaměřené instituce, které zpracovávají velké objemy dokumentů, které je nezbytné kvalitně a konzistentně indexovat. V řadě případů se však jedná o dokumenty, u kterých je dostupný pouze komprimovaný text (např. abstrakt), a které je tudíž žádoucí indexovat.
3. Zpřístupňování plných textů uživatelům a legislativně právní problematika, konsorcia, cenová politika
Zpřístupňované plné texty mohou mít v zásadě dvojí podobu: mohou existovat volně, nebo jsou licencované (přístup formou licencí).
Legislativa zatím ve většině zemí neumožňuje bezproblémově zpřístupňovat
elektronické zdroje, které nejsou volné - zákon o povinném výtisku ve většině
zemí nezahrnuje elektronické publikace on line, většinou se poskytují tyto
zdroje na principu dobrovolnosti a na základě individuálních smluv.
Někde
jsou zahrnuty pouze off-line zdroje (USA, Rakousko, Německo, Francie, ČR,
Švédsko. V Kanadě, JAR, Dánsko, Švédsko, Norsko, jsou do zákona o povinném
výtisku zahrnuty i elektronické zdroje. Příprava pozměňovacích návrhů:
Austrálie, Japonsko, Rakousko, Německo, Francie, Švédsko, VB (návrh nového
zákona prošel v parlamentu), ČR. Existuje dokument CENL/FEP (Conference of
European National Libraries/Federation of European Publishers) - Mezinárodní
deklarace k odevzdávání elektronických dokumentů do konzervačních fondů). Se
zpřístupňování plných textů souvisí i problematika autorských
práv.
Problematikou autorských práv se zabývá EBLIDA (European Bureau of
Library, Information and Documentation Associations) a WIPO.
Konzorcia a licence
Pro přístup elektronickým zdrojům zejména k plným textům článků se zakládají konzorcia a uzavírají licenční smlouvy (národní, plošné, individuální pro instituci) s agregátorem event. přímo s nakladatelem. Výhody: získání zdrojů jinak nedostupných, přístupu malým institucím/pracovištím, příznivější ceny, využití centrálních finančních zdrojů, levnější provoz (administrativní a organizačně-technické výhody), spolupráce.
Cenová politika (cit článek Národní knihovna, 2003?)Poplatky, které se váží na proces vyhledávání, jsou účtovány databázovým centrem na měsíční/roční bázi nebo časově jinak. Částky mohou být fixní nebo variabilní. Nejčastější způsoby úhrady:
- předplatné (flat-fee, fixed-fee, all-you-can-eat, subscription) - neomezené využívání databáze nebo skupiny databází za fixní periodické platby. Předplatné není obvyklé u koncových uživatelů, ale spíše u korporativních uživatelů
- platby jen za uskutečněné operace (pay-as-you-go) .
Poplatky z a výstupy se řídí dohodou mezi producentem databáze a on-line službou za:
- zobrazený záznam/dokument (display charge) - rozdílné jsou ceny pro různé databáze a různé formáty zobrazení.
- vytištěný záznam/dokument (print charge) - za záznamy vytištěné offline (v databázovém centru) nebo online (u uživatele)
- přetažený záznam/dokument (download).
Poplatky za speciální služby: průběžné rešerše (SDI či Alerts), podle předem zadaných profilů, DDS (document delivery services) klasicky nebo on-line. Různé sekundární analytické funkce, např. seřazení výsledků podle relevance, automatický přenos zvolených deskriptorů ze záznamů v rešeršní odezvě do jiné sady databází, různé frekvenční analýzy aj. Tyto sofistikované funkce jsou velmi užitečné pro zpracování informací a databázová centra proto za ně vybírají zvláštní poplatky nad rámec běžných poplatků.
Slevy pro časté uživatele, multiuživatelské licence, (vliv celekový počet uživatelů, velikost instituce, počet potenciálních uživatelů, součaně vyhledávajících uživatelů, konzorcia, speicální skupiny.
Způsoby informování uživatele o cenových relacích :Faktura a výpis z účtu u databázového centra (monthly invoice) jsou zasílány uživatelům obvykle každý měsíc. Výpis běžně obsahuje detailní rozpis jednotlivých relací a poplatky za ně v chronologickém pořadí.
Současné trendy v cenové politice:- eliminaci poplatků za connect time
- specifikaci cen a produktů pro různé tržní segmenty - ceny šité na míru pro konkrétní situace
- předplatitelské kontrakty pro korporativní zákazníky
- platby za výstupy pro koncové uživatele
- orientaci na koncového uživatele - zjednodušení cenových struktur, nabídka služeb přes portály, platby kreditní kartou
- propracovaný systém slev - množstevní slevy, slevy pro akademické instituce, pro nové uživatele, pro studenty, atd.
- poskytování některých služeb zdarma - propagační akce (hrazené z reklam), tréninkové a cvičné databáze
Využití proxy pro přístup k licencovaným zdrojům mimo rozsah IP
adres.
Výhoda připojení přes proxy server je pro uživatele pracující mimo
domovský rozsah IP adres, např. z domova, z internetové kavárny, ze zahraničí,
obrovská. Při připojení přes proxy server uživatel může přistupovat ke všem
službám a databázím s přístupem omezeným, licencovaným na použití v rámci
domovské instituce - knihovny, univerzity, apod..
4. Zpřístupňování plných textů v zahraničí a aplikace některých výšeuvedených standardů a nástrojů v zahraničí
Některé systémy a služby zpřístupňující informace o článcích v zahraničí jsou důkladně popsány ve zprávách programového projektu Souborná databáze kooperačního systému článkové bibliografie - optimalizace integrace a správy heterogenních dat. V předkládané zprávě jsou dále v tomto směru užity některé výsledky průzkumu v rámci programového projektu.
Lze shrnout, že kooperační systémy zabývající se zpřístupňováním článkových informací a článkové bibliografie se vyvíjely a existují zejména v zemích bývalého východního bloku (souborné katalogy článků v Rusku aj.). Články jsou zpřístupňovány zejména v severských zemích (Švédsko-Libris, Dánsko - Basis, Norsko-Bibsys, Finsko - Arto). Velké článkové databáze se budují v Holandsku, Španělsku, Německu, Gruzii, Litvě, Rusku, Slovinsku, Makedonii aj.). Poměrně kompletní přístup k elektronických časopisům nabízí OCLC First Search Electronic Collection Online. Kvalitně zpřístupňují plné texty Ingenta, ProQuest, EBSCO, Wilson Web aj. K dispozici jsou časopisecké zdroje na nakladatelských serverech, tituly vědeckých časopisů s volným přístupem k obsahům a abstraktům, někde i k plným textům, denní tisk a časopisy populární, popularizační i odborné včetně jednotlivých článků. Plné texty jsou zpřístupňovány jak soukromými společnostmi, tak knihovnami v rámci portálů, digitálních knihoven, archívů, multioborových i oborových databází. Jde o databáze konkrétních vydavatelů, agregátorů nebo servery konkrétních titulů.
Uživatelé v České republice mají dnes přístup k zahraničním informacím o
článcích různého typu z hlediska formy i obsahu díky programu MŠMT "Informační
zdroje pro výzkum a vývoj" (LI), který byl vyhlášen v září 1999 na čtyřleté
období (2000-2003). Cílem bylo zajistit systematickou podporu financování
oborových a polytematických informačních zdrojů, které si většinou jednotlivé
instituce nemohou dovolit. Přehled možné najít na www stránkách MŠMT, Portálu STM (projekt LI01018).
Národní knihovna ČR se koncem roku 2002 zapojila do projektu Univerzitní
knihovny v Regensburgu. Elektronische Zeitschriftenbibliothek (EZB).
Nová
online česká služba Infozdroje.cz obsahuje údaje o projektech zahrnujících nákup
elektronických informačních zdrojů realizovaných v letech 2000-2003 v rámci
grantového programu LI "Informační zdroje pro výzkum a vývoj". Infozdroje.cz obsahují
informace o všech produktech a službách dostupných díky financování v rámci
tohoto programu.
Některé aplikace OpenURL
Společnost Ovid uvedla službu Ovid OpenLinks ("universal link resolver") - službu, která umožňuje generovat propojení mezi informačními zdroji a službami podporujícími standard OpenURL ( vytváření linků na plné texty, document delivery services, library holdings a volně dostupné zdroje na Internetu. Služba Ovid Online je tak propojena na plné texty článků více než 8500 časopisů od mnoha vydavatelů a agregátorů.
Bibliografické záznamy přístupné v databázích od firmy H.W.Wilson jsou propojeny pomocí funkce WilsonLink (OpenURL) s plnými texty článků v elektronické knihovně JSTOR, která obsahuje více než 320 časopisů zaměřených na humanitní a společenské obory. Firma aplikovala též vyhledávací technologii Verity.
Nová verze vyhledávacího prostředí ProQuest - je zavedeno základní
vyhledávání a pokročilé, též nabídky Search Tips a Browse Topics. Součástí
služby Browse Topic je zároveň tezaurus s možností přímého vyhledávání. Výsledky
hledání je nyní možné řadit podle aktuálnosti nebo podle relevance. Další
novinkou je i členění výsledků podle typu publikaci, ze které dané záznamy
pocházejí (magazines, scholary journals, trade publications, newspaper and
reports). Nová je rovněž i forma zobrazení výsledků, která byla zjednodušena a
zpřehledněna.
Podpora technologie OpenURL usnadňuje odkazování jak na další
elektronické zdroje vlastněné vlastní knihovnou, tak i odkazování z
bibliografických databází na plné texty dostupné v rámci ProQuestu. Databáze
byla do jisté míry inspirací pro koncepci báze ANL FULL.
Příklad aplikace OpenUrl v UKOLN (Andy Powel, 2001)
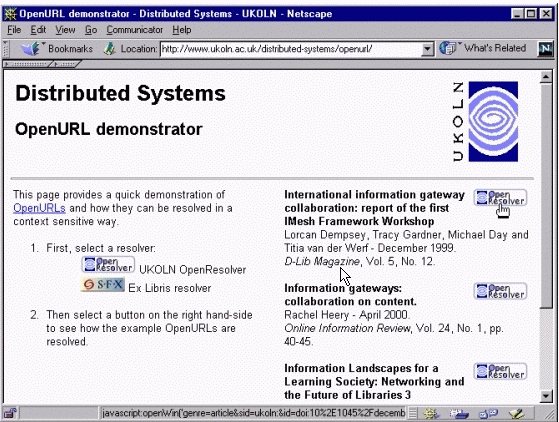
Andy Powell describes UKOLN's OpenResolver, a freely available demonstration OpenURL resolver.
Systém CrossRef a DOI (Anny Brand, Publishers International Linking Association, 2001)
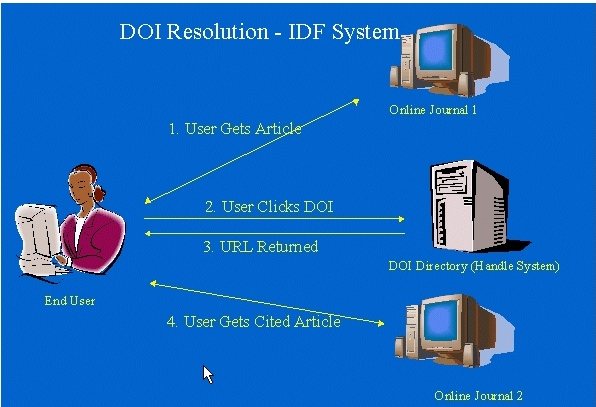
Některé projekty, databáze, služby, konzorcia
JSTOR - Journal StorageMezinárodní nevýdělečné konsorcium zaměřené na digitalizaci a zpřístupnění klíčových amerických humanitních vědeckých časopisů (v současnosti je k dispozici databáze 117 časopisů z Arts & Science Collection, obsahující všechny články od prvního čísla časopisu, s retrospektivou do minulého století, až po současnost).
IBZ - Internationale Bibliographie der Zeitschriftenliteratur
Mezinárodní článková bibliografie ze všech vědeckých oborů je nově nabízena i na CD-ROM. Příprava její tištěné verze byla zahájena již v roce 1840 v Lipsku a k roku 1896 se datuje její první vydání. Od té doby je pravidelně vydávána až do současnosti. Pětiletá kumulace let 1989-1993 na CD-ROM obsahuje 60 svazků tištěné verze IBZ s více než 2,7 miliónu záznamů. Od roku 1994 vycházejí samostatné ročníky IBZ na CD-ROM nabízející přes 120 000 článků z více než 6 000 titulů periodik. Jednotlivé záznamy obsahují autorské a názvové údaje o článku, klíčová slova, popis periodika, oborové zařazení obsahu článku, ISSN a ISBN. Software umožňuje práci s databází v jazyce německém i anglickém. Retrospektiva od roku 1983 (on-line verze).
Zpřístupnění plnotextových databází odborných zahraničních periodik na základě programuOpen Society Institute EIFL-Direct - plošná multilicence. Plné texty celkem cca 3300 časopisů od r. 1990 a další inf. zdroje (abstrakty, zpravodajství, příručky) především z oblasti sociálních a humanitních věd od EBSCO Publishing, jednoho z předních světových dodavatelů el. a tištěných časopisů, nabízené ve 4 dílčích databázích:
- Academic Search Elite (společenské a humanitní vědy)
- Business Source
Premier (ekonomie, finance, management, účetnictví, mezinárodní obchod)
-
Newspaper Source Plus (přes půl miliónů článků z více jak 100 novin v
angličtině)
- MasterFILE Premier (obecně zájmové tituly, obchod, zdraví,
kultura)
Zahrnuje i databázi Medline z oblasti lékařství a biomedicínského
výzkumu.
Služba OCLC FirstSearch s přístupem k plným textům OCLC Base Package with Full Text od organizace OCLC. Služba FirstSearch kombinuje funkce souborných katalogů, meziknihovních služeb, dodávání dokumentů a přístupu k elektronickým plným textům dokumentů.Kromě souborného katalogu (WorldCat) je zahrnut přístup do cca 12 dalších databází: ArticleFirst (bibliografické citace článků z cca 13.000 periodik), ContentFirst (seznamy obsahů periodik), NetFirst (bibliografické údaje o odborných zdrojích na Internetu, včetně abstraktů a klasifikace), PapersFirst (referáty ze světových konferencí, kongresů, sympozií, výstav a workshopů od 1983), ProceedingsFirst (seznamy obsahů sborníků z vědeckých konferencí), UnionLists (souborný katalog periodik s uvedenými lokacemi), WilsonSelect (plné texty článků z 800 periodik), WorldAlmanac MEDLINE (medicínská informace), ERIC (bibliografie literatury z oblasti vzdělávání) a další.
Služba OCLC CORC Cooperative Resource Catalog poskytuje nástroj pro automatickou katalogizaci elektronických zdrojů přímo na webu (vyhledávání, vytváření a editace záznamů) ve formátech MARC a DC. Na jeho testování se podílelo více než 450 knihoven z celého světa. Databáze vznikla ze záznamů původně uložených v bázích OCLC InterCat a NetFirst.
Bude zahájena testovací fáze zpřístupnění zkrácených verzí vybraných záznamů z WorldCatu prostřednictvím vyhledávače Google (a dalších spolupracujících webových stránek).
V rámci služby kooperují kromě jiných institucí knihovny v jednotlivých
státech USA. Tzv. lokátorové záznamy odkazují na zdroje, které uchovávají úřady
státní a místní správy nebo státní instituce. Pomocí lokátoru se zjišťují,
popisují a zpřístupňují informace o zdroji.
V rámci systému GILS existuje
trojí způsob tvorby záznamů: klasický způsob (ruční), konverze (převod záznamů z
jiných bází dat), automatizovaný způsob (extrahování metadat). Posledně
jmenovaný způsob spočívá v automatizovaném vytváření záznamů při prohledávání a
indexaci zdrojů (metadat a samotného textu). Z tohoto důvodu je nutné, aby
se metadata stala součástí www dokumentů. Dosavadní editory pro tvorbu
webovských dokumentů neumožňují vytvářet a automaticky začlenit prvky metadat,
je nutné formát pro metadata ručně vložit do zdrojového
dokumentu.
Předpokládá se, že formuláře nahradí efektivnější software pro
generování metadat. Tento systém by mohl být v mnoha směrech inspirativní i pro
nás ( je založen na kooperaci a automatizovaném zpracování dat).
Připravují se nástroje pro převod dat Dublin Core/MARC Library of Congress:
Dublin Core/MARC/GILS Crosswalk, které využívají prvky DC v
katalogizaci.
V rámci projektu Nordic Metadata byl vytvořen konvertor dat, který je
schopen generovat záznamy ve formátech MARC severských zemí a USMARC ze
zdrojových údajů DC.
Projekt Renardus: Akademický tematický portál konsorcia 12-ti institucí. Řešen v rámci 5 tého rámcového programu EU "Technologie pro informační společnost". Renardus má umožňovat paralelní pohyb uživatele po tematických portálech (metadata DC, Z39.50, DDC).
Architektura pro britskou národní digitální knihovnu UK DNER (Distributed National Electronic Resource). Cíl: Národní digitální knihovna pro vyšší a další vzdělávání, distribuovaný zdroj informací pro vzdělávání a výzkum, řízený soubor zdrojů, heterogenní povahy, bibliografická data, obrázky, texty, video, dostupnost místní i dálková. Fondy jsou typicky ve formě sbírek: primárních dat, sekundárních dat (tématické portály, knihovní katalogy, databáze) (Z39.5, portály, Bath profil, XML).
Program Cobra a CoBRA+ v rámci EC se zaměřují na problematiku elektronických publikací a sdílení dokumentů v sítích - protokoly, standardy, uživatelské rozhraní, elektronické publikování, dostupnost a dlouhodobé uchování elektronických zdrojů, vícejazyčné indexování. Jedním z projektu je projekt Biblink , který se zabývá vybudování vazeb mezi národními bibliografickými agenturami a vydavateli elektronických zdrojů s cílem společně vytvořit informace o těchto dokumentech využitelné v obou oblastech.
Příklady systémů automatické indexace Jedná se o plně funkční systémy, které jsou provozovány rutinně nebo v testovacím provozu. U jednotlivých systémů není označeno, zda se jedná o systémy pracující na bázi automatické extrakce nebo automatického přiřazování, protože většina systémů tyto dva přístupy kombinuje.
Media On Line Project
Media On Line Projekt byl realizován v letech 1996-1999 v Belgii, jeho financování bylo zajištěno v rámci programu Vlaams Actieprogramma Informatietechnologie, řešitelem bylo ICRI-Interdisciplinary Centre for Law and Information Technology na Katolické univerzitě v Lovani (Katholieke universiteit Leuven) ve spolupráci s dalšími institucemi. Projekt byl zaměřen na online publikaci článků z různých oborů (politika, ekonomika, finance, životní styl, umění, sport atd.), které bylo třeba z důvodu průběžného dodávání uživatelům rychle a efektivně indexovat. Vzhledem k tomu, že pro indexaci byly používány maximálně tři obecné deskriptory na každý článek, jednalo se spíše o klasifikaci. Kromě automatické indexace bylo řešeno i automatické abstrahování. Souhrnem lze říci, že testování automatické indexace proběhlo v tomto projektu úspěšně, většina použitých metod byla ověřena jako účinná. Pro zvýšení efektivity systémy by bylo ještě možné v první fázi aplikovat lematizaci.
Center for AeroSpace Information (CASI) spadající pod americkou vládní organizaci NASA už od konce 70. let 20. století vyvíjí a rutinně používá MAI Tool (Machine-Aided Indexing Tool) pro automatickou indexaci technických zpráv a dalších dokumentů. Tento systém je typický příklad jednoduchého, ale robustního a účinného nástroje, který slouží jako automatická podpora intelektuální činnosti indexátora. Systém na základě termínů z přirozeného jazyka vybírá za pomoci znalostní báze (knowledge base) deskriptory NASA tezauru (NASA thesaurus) a předkládá je k posouzení indexátorům, kteří provedou výsledný výběr a přiřazení deskriptorů k záznamům. V rámci statistické analýzy jsou jedno- a víceslovná spojení převzatá z textu dokumentu porovnávána s obsahem znalostní báze a na základě jednoduchých pravidel jsou navrhovány kandidáti na indexační termíny (deskriptory NASA tezauru).
Další některé dílčí databáze
ERIC, MEDLINE, Academic Search Premier, Regional Business News, Newspaper Source, Business Source Premier, MasterFILE Premier.
5. Mezidnárodní akce a související problematika s projektem
Problematika bibliografie, zpřístupnění elektronických zdrojů, informačních
technologií se řeší v příslušných sekcích a skupinách. Zpřístupněním seriálových
publikací se zabývá Serial Publications Section (standardy, kooperace,
dostupnost a akvizice, copyright, archivace, rozvoj a management sbírek, vztah s
nakladateli a dalšími organizacemi zabývajícími se vydáváním, zpřístupňováním,
distribucí seriálů, reprezentace knihoven na "technological
marketplace
Jednou z aktivit IFLA je zmapovat situaci týkající se
zpracování a zpřístupnění seriálových publikací pomocí IFLA-Directory of Serial
Content Databases and Awareness Services for Serial Content. V rámci tohoto
průzkumu byly poskytnuty informace o zpracování článků v ČR.
Austrálie
Australské zkušenosti prezentované na konferenci: National
Bibliographic Database, de facto australská národní bibliografie,
přistupuje k novému modelu bibliografické služby, která kombinuje tradičně
produkovaná bibliografická data s dodáváním metadat od autora či vydavatele.
Koncept předpokládá získávat data z těchto zdrojů: National Bibliographic
Database, National Discovery Service, národního repozitáře metadat. National
Bibliographic Database obsahuje: katalogizovaná data, katalogizační záznamy
vzdálených zdrojů archivované v National Library, digitalizované dizertace,
katalogizační záznamy od prodejců ("vendors", kteří mohou stát mezi producentem
a kupujícím) elektronických zdrojů a služeb. The Rource Discovery Service
obsahuje: metadata z elektronických archivů, metadata ze "subjekt gateways",
metadata elektronických služeb - výchova a vzdělání, kultura. Uživatel se tak
bude moci vybrat tištěnou i elektronickou formu dokumentů.
Tento přístup v
mnohém připomíná metody, řešené v rámci předkládaného projektu .
Švédsko
Velmi podobný model jako je v předkládaném projektu je také vyvíjen v The Royal Library - National Library of Sweden. Národní bibliografie ve Švédsku je částí LIBRIS. Model je zatím aplikován u elektronických forem knih, předpokládá se i pro periodika a noviny. Metadata vyplňovaná do formuláře jsou posílána vydavateli do LIBRIS, konvertována do XML databáze a MARC 21 (LIBRIS). Textový soubor je dále přes FTP posílán do Royal Library´s digital archive. V Royal Library jsou záznamy z LIBRIS doplněny předmětovým popisem. V příspěvku se konstatuje, že efektivnější by bylo obdržet metadata přímo od distributorů bez dlouhého vyplňování www formuláře. Údaje od vydavatelů již existují v určité podobě a vyplňování formuláře je nadbytečné.
Zpracovaná data je možno opět poslat vydavateli. Formáty dat: MARC, ONIX, Dublin Core.Slovensko
Na Slovensku vychází Slovenská národná bibliografia podobně koncipován jako Česká národní bibliografie. Slovenské články 1978 - 1997 (cit: Rozpisový rad článkov popisuje články a state z vybratých periodík a zborníkov slovacikálneho charakteru. Databáza obsahuje záznamy od roku 1978 a jej súčasťou od roku 1981 je aj rozpis článkov zo sérií C (mapy), H (hudobniny) a J (audiovizuálne dokumenty). Databáza obsahuje takmer 685 000 záznamov). Slovenské články od roku 1998 (cit: Naväzujú na predošlú databázu a obsahujú záznamy o článkoch zo slovenských novín, časopisov a zborníkov od roku 1998 do súčasnosti. Kolekcia predstavuje viac než 160 000 záznamov.
Súborná databáza regionálnej bibliografie Košice, Rožňava, Trebišov, Spiš obsahuje články těchto institucí. Je zveřejněna na stránkách Gemerské knižnice Pavla Dobšinského. "V databáze sú bibliografické záznamy článkov z novín a časopisov prevažne od roku 1994, ktoré sa týkajú regiónov Košice, Rožňava a Trebišov".
Rusko viz dále.
TEL
The
European Library Project (TEL) je zaměřen na národní knihovny a CENL
(Conference of European National Libraries), na přístup k sbírkám dokumentů na
základě kooperace (spolupráce s nakladateli, povinný výtisk, business modeling,
metadata, Z.39.50 a XML, standardy, služby). V r. 2001 řešitelka projektu dodala
údaje pro Questionnaire for the European national libraries to determine the
current status of digital deposits. Výsledkem dotazníkové akce je publikace TEL
Digital deposits state of the art review. Dotazník mapuje situaci kolem
povinného výtisku, spolupráce s vydavateli/nakladateli, zpracování el.
dokumentů, zpřístupnění a archivace.
Z dotazníku: pouze 5 národních knihoven
denně aktualizuje dokumenty pro digitální knihovnu on-line (Čeká republika,
Dánsko, Německo, Nizozemí, Velká Británie). Pracovní linky jsou v ČR, Německu,
Lotyšsku, Nizozemí, Švédsku. 3 knihovny jsou v kontaktu s IT společnostmi. 4
knihovny automaticky konvertují dodaná data (ČR, Německo, Makedonie, Nizozemí).
Většina knihoven používá deskriptivní/bibliografická metadata.
Problematika Tel na Elag 2003
Řeší se problematika distribuovaného vyhledávání v různých zdrojích. Snaha najít vazbu mezi skrytým a otevřeným webem. V pro otevřený web je vhodný pro popis zdrojů DC, OPACy lze také převést na DC (možno doplnit). Lze tak dostat sourodý výsledek vyhledávání a vyřešit problém "dvou" webů. Jednotlivé sbírky by měly být popsány na této úrovni, takže vyhledávání v OPACích by probíhalo nejprve na této úrovni.
V č. 10 /2002 News form the IFLA Round Tabel of Newspapers jsou publikované články o některých projektech týkajících se digitalizace a zpřístupnění novin. Národní knihovna v Norsku se zúčastní integrovaného projektu LAURIN pro digitalizaci a indexaci novinových výstřižků (Norsko, Austrálie, Itálie, Španělsko, Švédsko, Německo).
Projekt TIDEN (Norsko, Švédsko, Grónsko, Dánsko) - Newspaper Library on the Net.
K těmto informacím připojuji informaci o zpřístupňování novin (cit Anděrová, 2003), která byla předmětem semináře Newspapers for Libraries. Newspapers and the press in Central and Eastern Europe: access and preservation (Berlin-Brandenburgische Akademie der Wissenschaften, 9.-10. 8. 2003), kterého jsem se zúčastnila. V řadě zemí střední a východní Evropy existují specializovaná pracoviště zabývající se uchováváním a zpřístupněním novin (tj. deníků, týdeníků a čtrnáctideníků) v návaznosti na projekty týkající se digitalizace a zpřístupnění těchto materiálů v celé šíři problematiky (technika pro převod tištěných dokumentů na různá média včetně automatické strukturace textu a automatického zpracování metadat). Na mnoha serverech je možno najít portály, které zpřístupňují tyto dokumenty často podle regionálního hlediska ze všech konců světa. V současné době se věnuje velká pozornost samizdatové a exilové literatuře, jejímu shromažďování, uchovávání a zpřístupnění. Stále potřebnější je kooperace na národní i mezinárodní úrovni. Noviny jsou zpřístupňovány v samostatných sbírkách nebo spolu se seriály, v rámci portálů a virtuálních knihoven, jsou budovány jejich rozsáhlé archívy. V některých zemích existuje stanovená strategie budování sbírek těchto informačních zdrojů.
Informace v novinách mapují ekonomický, sociální, kulturní a politický vývoj společnosti z různých hledisek a jsou někdy podceňovány. Jejich využití je možné i pro vědeckovýzkumné účely v těchto oblastech.O nutnosti zabývat se problematikou novin svědčí i fakt, že byla v r. 2002 založena v rámci IFLY Sekce pro noviny - Newspapers Section. Sekce se zabývá strategií, popisem, digitalizací, novými technologiemi pro zpracování a zpřístupnění novin. Na stránkách IFLY je vystavena doporučení pro popis novin International Guidelines for the Cataloguing of Newspapers.
Příspěvky podrobně zmapovaly situaci z globálního pohledu s ohledem na specifika v angloamerické oblasti, ve východní Evropě a částečně střední Evropě. V angloamerické oblasti se věnuje velká pozornost budování sbírek těchto dokumentů. např. National Library of Australia vystavuje na svých stránkách Australian Newspapers on line. Pozornost též zaslouží australská strategie budování sbírek Collection Development Policy. Podobně buduje sbírku novin National Library of Canada. Strategie budování sbírek v rámci veřejných, universitních, akademických knihoven, školních, národních a státních knihovnách v rámci USA je zveřejněna pod názvem Directory of Collection Development on the Web. Strategii sleduje i British Library. V rámci projektu COSEELIS se zpracovává UNION list of Slavonic and East European Newspapers in British Libraries. Významné jsou i aktivity týkající se rozšíření práva povinného výtisku na elektronické publikace v rámci britského parlamentu. V Německu je budovaná Zeitschriftendatenbank ZDB.
Na internetu existuje množství portálů a serverů zpřístupňujících noviny často doplněné aktuálním zpravodajstvím. Společnost Worldpress.com nabízí 1117 deníků publikovaných v 192 zemích.Newspapers brom around the world poskytuje linky na tituly uspořádané regionálně v rámci USA, v různých oblastech světa, Kanadě. V Actualidad.com jsou noviny vyhledatelné podle kontinentů. Online newspapers.com nabízí tisíce světových novin vyhledatelných podle regionu. News and Newpapers on-line je služba na University of North Carolina in Greenboro (vstup přes individuální titul, region, zemi).
Služby ve východní Evropě. V ABYZ News Links je obsažen výběr titulů z evropských zemí aj.
oblastí světa. NewsDirectory.com obsahuje evropské zdroje, swnewsherald.com zahrnuje
zdroje východní Evropy a pobaltských zemí, megamallandmall.com zahrnuje střední a východní Evropu. Inkpot Newspapers
Link obsahuje noviny 17 východoevropských zemní a Ruska aj. regionů.
Integrum je nejrozsáhlejší
databázová služba poskytující služby on-line v Rusku - obsahuje 4000 databází
(přes 140 000 000 dokumentů, 15 000 nových dokumentů denně, archívy národních a
regionálních novin, časopisů, TV a rozhlasových pořadů, zprávy a archívy
hlavních národních a mezinárodních informačních agentur, plné texty ruských
klasiků, dokumenty audiovizuální) - plnotextové vyhledávání, media monitoring
service, placená služba, automatické překlady.
Zajímavé byly příspěvky z
ruských knihoven. Konstantint M. Suchorukov (Head of National
Bibliography Departement in the Russian Book Chamber) and A. Dzingo (Deputy
Director of the Russian Book Chamber): Work with newspapers at the Russian book
Chamber: results, problems and prospects - příspěvek podrobně analyzující
situaci ve vydávání novin v Rusku, problematiku povinného výtisku a
zpracování článkové bibliografie - Letopis´ gazetnych statej - s týdenní
periodicitou (cca 50 titulů novin). Dále vychází Letopis´ žurnal´nych statej a
Letopis´ recenzij. Bibliografie vydává Rossiskaja knižnaja palata . Elektronické
bibliografické báze obsahují novinové články od r. 1988, časopisecké články od
r. 1991.
Některá z další vystoupení se týkala zpřístupnění sbírek alternativní a samiszdatové literatury a dalších novinových sbírek. Claus Gravenhorst (Cheif Product Management CCS Hamburg): Automated retroconversion of newspapers into fully tagged XML. Tento zajímavý příspěvek se týkal problematiky mikrofilmování, digitalizace včetně metod strukturace textu , extrakce a generování metadat na základě metody vyvinuté CCS - Content Conversion Specialist. Analyzoval technologii umožňující vytváření a archivování strukturovaných dat během procesu retrokonverze. Tato technologie je použita v projektu METAe.
Z dalších vystoupení na kongresu, která se týkala problematiky novin. Denise Rosemary Nicholson (Copyright Services Librarian, University of the Witwatersrand, Johannesburg, South Africa):What has copyright got to do with newspapers? - A South African Perspective. Charles Opppenheim (Loughborough University, UK): Newspaper copyright developments: a EU and UK prespective.
V obou vystoupeních byly konstatovány malé pokroky týkající se oblasti zpřístupňování novin s ohledem na copyright, platné zákonné normy komplikují zpřístupňování článků z novin, které de facto podléhají dvojnásobné kontrole z hlediska autorských práv: autorská práva vydavatele novin a autorská práva jednotlivých autorů článků. Potěšitelná je aktivita ve Velké Británii směrem k elektronickému povinnému výtisku.
Sekci pro noviny jsem poskytla informace o projektech týkajících se zpracování článků a zpřístupnění článků v rámci oddělení analytického zpracování NKČR, Kooperačního systému článkové bibliografie, báze ANL a ANL FULL V této sekci mně bylo nabídnuto členství.
V r. 2003 jsem se také zúčastnila sympózia Infos 2003. Zaujal mne fakt, kolik úsilí se na Slovensku věnuje retrokonverzi článků.
A.2.3 Současný stav v ČR
Následující materiál poskytuje přehled organizace zdrojů na českém internetu, které souvisejí nebo perspektivně budou souviset se zpřístupněním plných textů. Některé z nich jsou analyzovány v analytické části zprávy.
Plnotextové zdroje zpřístupňované v rámci Jednotné informační brány - zatím většinou zahraniční provenience, článková bibliografická báze ANL s propojením na plné texty v ANL FULL a na volá www periodika
Plné texty české provenience a zdroje související se zpřístupněním českých plných textů
Pozn.: Plné texty zahraniční provenience zpřístupňované v rámci programu LI nejsou specificky označeny - viz MŠMT, Portál STM
PřístupNěkteré instituce na svých stránkách poskytují linky na volně dostupné zdroje české provenience na www, na zdroje, které vydávají nebo na plnotextové zdroje zakoupené. Jedná se zatím o dílčí záležitosti v tomto přehledu specificky neoznačené.
Plné texty v českých novinách a časopisech (báze ANL a ANL FULL - NKČR, ANOPRESS, WWW), archivy
| ANL FULL, ANL | Statistika 1 - linky, graf 1 |
| ANOPRESS | |
| WWW | |
| ANL | Statistika 2 - linky, graf 2 |
| WWW |
Oborová periodika (volně na www)
Informační agentury
Newton IT
Anopress IT
ČTK
Parlament, Senát
Digitální knihovna "Český parlament"
Dokumenty Senátu
Zpravodajské servery
České noviny
IDNES
Lidové
noviny
iHNED
Právo
Mojenoviny
Volný
Seznam Dnes
Nakladatelství, vydavatelství, archiv webu
Sagit
Tigis
Portál
Muzikus
Vydavatelství Economia
Akademie věd ČR
Nakladatelství Karolinum
Webarchiv
Internetové vyhledávače
http://www.seznam.cz/
http://kompas.seznam.cz/
http://www.uzdroje.cz/
http://www.centrum.cz/
http://www.redbox.cz/
http://www.quick.cz/
http://www.atlas.cz/
http://www.najdito.cz/
http://www.alenka.cz/
Obory
Katalog
vysokých škol v ČR
Knihovnictví
(NKČR)
Knihovnická
periodika
Automatizovaný systém právních informací (ASPI)
Automatizovaný systém právních informací (ASPI)
Literární věda
Literatura
Archiv literárních časopisů
(AVČR)
E-archiv J.
Peterky
Organizační schéma AV ČR
Knihovny a instituce zpracovávající a zpřístupňující informace o plných textech. Znakem * jsou označeny instituce spolupracující v Kooperačním systému článkové bibliografie - KOSABI (Báze ANL, ČNB), ** nově přistupující instituce do kooperace - perspektivně, *** kooperující instituce nepřispívající do báze ANL.
Národní knihovna ČR*
Moravská zemská knihovna*
Krajské knihovny
Jihočeská vědecká knihovna v Českých Budějovicích*
Krajská knihovna F. Bartoše ve
Zlíně**
Krajská
knihovna Karlovy Vary**
Krajská vědecká knihovna v Liberci*
Krajská knihovna v
Pardubicích**
Krajská
knihovna Vysočiny**
Moravskoslezská knihovna v Ostravě*
Studijní a vědecká knihovna v Ústí nad
Labem*
Studijní a vědecká
knihovna Plzeňského kraje*
Studijní a vědecká knihovna v Hradci Králové*
Středočeská vědecká krajská knihovna v
Kladně*
Vědecká knihovna v
Olomouci*
Specializované knihovny a instituce
Divadelní
ústav
Knihovna ČGS**
Knihovna uměleckoprůmyslového
muzea
Multikulturní centrum Praha
Národní filmový archiv
Národní pedagogická knihovna Komenského - Ústav pro informace ve
vzdělávání*
Národní lékařská
knihovna***
Parlamentní knihovna
Státní technická knihovna*
Ústav zemědělských a
potravinářských informací*
Veřejné knihovny spolupracující ve Sdružení uživatelů knihovních systémů LANius
Přehled kooperace Lanius **
Sdružení Lanius - Souborný katalog článků SKAT
České vysoké školy
Adresář
vysokoškolských knihoven
Katalog
vysokých škol v ČR
Akademie věd ČR
Časopisy vydávané AVČR
Organizační schéma AV
ČR
Církevní knihovny
Česká biskupská
konference
Centrální katolická
knihovna
Podnikové knihovny ?
Bibliografie
AVČR - ústavní
bibliografie
Česká národní
bibliografie
Bibliografia Medica Čechoslovana
Bibliografie
české literární vědy
Bibliografie
článků o divadle
Pedagogická bibliografie
Zemědělská
bibliografie
Souborné katalogy a databáze článkové (zdroje české
provenience)
Souborná
databáze Kooperačního systému článkové bibliografie ANL
Báze ANL FULL
Databáze ANSKAT systému
Lanius
Další souborné katalogy a databáze (obsahují též zdroje zahraniční
provenience)
Centrální
evidence zahraniční literatury (CEZL)
Souborný katalog ČR
Souborný katalog ČVUT
Souborný katalog
Univerzity Karlovy
Souborný katalog Univerzity Palackého
Soupis zahraničních časopisů
dostupných na území ČR
Souborný katalog
odborné literatury veřejných knihoven (SKAT)
Vysokoškolské práce
na UK
Virtuální Souborný katalog Univerzity Karlovy
Databáze autorit
Databáze
Národních autorit NKČR
Databáze REGO
Databáze REOS
Databáze
autorit Centrální katolické knihovny
Digitální knihovny
Digitální knihovna (VK v Olomouci)
Digitální
knihovna (NKČR)
Manustcriptorium
(NKČR)
Brány a portály aj.
Agronavigator
Česká škola
Divoch
Elektronické informační zdroje na vysokých školách ČR
(AKVŠ)
Indoš
Infozdroje.cz
Econlib
Literární servery a jiné
Jednotná informační brána
MEDVIK
Moje škola
PEC
Portál
ČGS
Portál STM
Portál veřejné
správy
ŠkolaOnLine
Elektronické dodávání dokumentů (není úplné)
Virtuální polytechnická knihovna
(STK)
Econlib
(CIKS -VŠE, CERGE-EI))
Virtuální medicínská knihovna MEDVIK
Národní knihovna
ČR( Digitální knihovna, DoDo)
ČVUT
UMPRUM
Národní
pedagogická knihovna J.A. Komenského
Vysoká škola
báňská
A.3 Cíl, vstupní data
Anotace (původní zadání - r. 1999)
Cílem výzkumného záměru je optimalizace přístupu uživatelů k plným textům dokumentů domácí i zahraniční provenience. Základem je propojení analytických záznamů o článcích s plnými texty, které jsou dostupné na Internetu a/nebo CD-ROM. Okamžitě bude k dispozici účinný rešerší nástroj - analytické záznamy zpracované v Kooperačním systému české článkové bibliografie, které jsou součástí České národní bibliografie. Jejich postupné propojení s plnými texty ústředních i regionálních periodik výrazně zvýší uživatelský komfort při jejich využití. Náplní záměru je i zpřístupnění plných textů zahraničních dokumentů v elektronické podobě. Zpřístupnění zahraničních zdrojů v NK výrazně rozšíří nabídku pro uživatele a umožní integraci dosud málo využívaných elektronických zdrojů do běžných služeb českých knihoven.
Korekce zadání (r. 1999)
Záměr se bude orientovat na zpřístupnění
především českých plných textů.
Vstupní data
- Vstupními daty pro bázi ANL jsou bibliografické záznamy článků z regionálních titulů vydaných v letech 1997 - 2000 zpracovávané v rámci KOSABI spolupracujícími institucemi.
- Vstupními daty pro bázi ANL jsou bibliografické záznamy zpracované v NKČR titulů vydaných v letech 1997-2003 v ALEPHu, plné texty vydané a zpracovaná v lince TTDE v letech 2001 -2003.
- Vstupními daty pro bázi ANL FULL jsou plné texty s metadaty vydané v letech 2001-2003, které vznikají v rámci linky zpracování bibliografických záznamů z plných textů při generování dynamických URL, za současného generování formátů UNIMARC, DC a jejich zpřístupnění v HTML XHTML a XML v bázi ANL FULL.
- Vstupními daty pro bázi ANL FULL jsou plné texty s metadaty vydané v letech 1997-2000 v regionálních titulech.
- Vstupními daty pro Portál WWW periodik jsou periodika strukturovaná oborově a regionálně
Zpět na Granty .
| 20.5. 2004 | Ivana Anděrová |