Zpracovala: PhDr. Ivana Anděrová, hlavní řešitelka
|
|
- OPTIMALIZACE INTEGRACE A SPRÁVY HETEROGENNÍCH DAT |
Souhrnná zpráva za rok 2001 |
A |
Konstatační část |
| A.1 | Rešerše |
| A.2 | Současný stav ve světě a v ČR |
| A.3 | Cíl, vstupní data |
B |
Analytická část |
| B.1 | Vlastní řešení |
| B.1.1 | Linka automatické indexace |
| B.1.2 | TOPIC a báze ANL FULL |
| B.1.3 | Standardizace - bibliografická metadata ve formátu UNIMARC, DC, HTML, XHTML, XML, propojení záznamů s plnými texty |
| B.1.4 | Skutečný stav propojení bibliografických záznamů s plnými texty |
| B.1.5 | Souborná databáze ANL Kooperačního systému článkové bibliografie (KOSABI) |
| B.1.6 | Česká národní bibliografie - řada Články v českých novinách, časopisech a sbornících na CD-ROM |
| B.1.7 | Management Kooperačního systému článkové bibliografie (aplikace MNG KOSABI) |
| B.1.8 | HW a SW podpora KOSABI a pro bázi ANL FULL |
| B.1.9 | Smluvní ošetření projektu a Kooperačního systému článkové bibliografie |
| B.2 | Přínos řešitele |
| B.3 | Posun znalostí |
C | Návrhová část |
| C.1 | Výsledky řešení |
| C.2 | Závěr |
| C.3 | Návrhy opatření |
D | Použití finančních prostředků |
| D.1 | Komentář |
| D.2 | Tabulky (vynecháno) |
E | Resumé a klíčová slova |
| E.1 | Resumé a klíčová slova v češtině |
| E.2 | Abstract and key words in English (vynecháno) |
F | Přílohy(vynecháno) |
| F.1 | Báze ANL v NK ČR |
| F.2 | Linka automatické indexace bibliografických záznamů z plných textů - bibliografická metadata pro bázi ANL (ALEPH) a plné texty s Dublin Core pro bázi ANL FULL (TOPIC) |
| F.3 | Server FULL.NKP.C |
| F.4 | Tituly v bázi ANL FULL, tabulka návěští pro vyhledání v poli dotaz, tabulka formulářových polí, topiky, citace článku. ČNB. Aplikace pro správu a údržbu KOSABI. ProQuest. EBSCO. |
Tištěné dokumenty:
1. KOSEK, J. XML pro každého : podrobný průvodce. 1. vyd. Praha : Grada 2000. 163 s.
2. OPPENHEIM, Charles and SMITHSON, Daniel. What is the hybrid library? Journal of Information Science. 1999, vol. 25, no. 2, s. 97-112.
3. Topic : systém pro inteligentní vyhledávání dokumentů. Praha : Tovek, 19?, 77 s.
4. ANDĚROVÁ, Ivana. Kooperační systém článkové bibliografie a propojení analytických záznamů s plnými texty - východiska a současný stav. Národní knihovna : knihovnická revue. 2001, roč. 12, č. 1, s. 26-37. Též dostupný z: http://full.nkp.cz/nkdb/index.html.
5. ANDĚROVÁ, Ivana. Současný stav a perspektivy kooperačního systému článkové bibliografie. Národní knihovna : knihovnická revue. 1995, roč. 6, č. 1, s. 39-42. Též dostupný z: http://full.nkp.cz/nkdb/index.html.
6. BRATKOVÁ, Eva. K otázkám pojmu, třídění a typologie internetových a webovských informačních zdrojů. Národní knihovna : knihovnická revue. 1998, roč. 9, č. 5, s. 262-276. Též dostupný z: http://full.nkp.cz/nkdb/index.html.
7. BRATKOVÁ, Eva. Metadata jako nový nástroj pro komunikaci webovských informačních zdrojů. Národní knihovna : knihovnická revue. 1999, roč. 10, č. 4, s. 178-195. Též dostupný z: http://full.nkp.cz/nkdb/index.html.
8. ČERVENÝ, Vlastimil. Vyhledávání v databázích plných textů. Národní knihovna : knihovnická revue. 1999, roč. 10, č. 1, s. 6-12. Též dostupný z: http://full.nkp.cz/nkdb/index.html.
9. PSOHLAVEC, Stanislav: Z39.50 versus (?) XML. Národní knihovna : knihovnická revue. 2001, roč. 12, č. 1, s. 45-46. Též dostupný z: http://full.nkp.cz/nkdb/index.html.
10. Záznam pro soubornou databázi : UNIMARC. Fyzicky nesamostatné části dokumentů. Tištěné monografie a seriály. 1. vyd. Praha : Národní knihovna České republiky, 1999. 45 s. (Standardizace ; č. 19). Též dostupný z: nkpnew.2b.cz/pages/page.php3?page=fond_anal_unim_opr.htm.
11. Záznam pro soubornou databázi : Výměnný formát. Fyzicky nesamostatné části dokumentů. Tištěné monografie a seriály. 1. vyd. Praha : Národní knihovna České republiky, 1999. 39 s. (Standardizace ; č. 20). Též dostupný z: nkpnew.2b.cz/pages/page.php3?page=fond_ann_vf_opr.htm.
Elektronické dokumenty
12. ANDĚROVÁ, Ivana. Programový projekt MK ČR "Souborná databáze Kooperačního systému článkové bibliografie - optimalizace integrace a správy heterogenních dat". Ikaros [online]. 2000, č. 10 [cit. 2000-12-01]. Dostupný z: http://ikaros.ff.cuni.cz/2000/c10/clanky.htm.
13. ANDĚROVÁ, Ivana: propojení analytických záznamů s plnými texty a optimalizace zpřístupnění plných textů. Rok 1999, 2000, 2001 [online]. Dostupný z:nkpnew.2b.cz/pages/page.php3?page=oazp_propoj.htm.
14. ANDĚROVÁ, Ivana.Souborná databáze Kooperačního systému článkové bibliografie - optimalizace integrace a správy heterogenních dat. Souhrnná zpráva za rok ... [online]. Dostupný z: http://nkpnew.2b.cz/pages/page.php3?page=oazp_grant.htm.
15. Biblink [online]. Bath (Anglie) : UKOLN, last updated 12-Jul-2000 [cit. 2001-03-14]. Dostupný z: http://hosted.ukoln.ac.uk/biblink/.
16. BRATKOVÁ, Eva. Bibliografické a plnotextové báze dat americké firmy H.W.Wilson pro společenské a humanitní obory: vyhledávání informací v systému WilsonWeb. Infomedia [online], 1998 [cit. 2001-11-14]. Dostupný z: http://www.inforum.cz/infomedia98/.
17. CASLIN 2001. Popis a zpřístupnění dokumentů : nová výzva [online]. Beroun, 27.-31. května 2001 [cit. 14.11.2001]. Dostupný z: http://www.caslin.cz:7777/caslin01/sbornik/index.htm.
18. CELBOVÁ, Ludmila. Informace o projektu registrace domácích internetových zdrojů nově na serveru WebArchiv. Ikaros [online]. 2001, č. 5 [cit. 2001-05-01]. Dostupný z: http://ikaros.ff.cuni.cz/2001/c05/webarchiv.htm.
19. CELBOVÁ, Ludmila. Elektronické zdroje publikované v síti Internet jako součást České národní bibliografie. Ikaros [online]. 2000, č. 6 [cit. 2000-06-01]. Dostupný z: http://ikaros.ff.cuni.cz/2000/c06/elzdroje.htm.
20. Cobra+ : Computerised Bibliographic Record Actions [online]. Boston Spa (Velká Británie) : COBRA+, 1997 [cit. 2000-04-10]. Dostupný z: http://portico.bl.uk/gabriel/en/projects/cobra.html.
21. Dieper : digitised European periodicals [online].Dostupný z: http://gdz.sub.uni-goettingen.de/dieper/home.htm.
22. DOI, the Digital Object Identifier System [online]. Kidlington (Oxford, Velká Británie) : International DOI Foundation, 1998, updated 4 April 2000 [cit. 2000-04-10]. Dostupný z: http://www.doi.org/.
23. Dublin Core Metadata Initiative [online]. Dublin (Ohio, USA) : OCLC, 2000 [cit. 2000-04-10]. Dostupný z: http://purl.org/dc/.
24. H.W. Wilson Company Selects Verity to Power the New WilsonWeb Site - the Premier Reference Resource for Librarians and Researchers [online]. Sunnyvale, Calif. and New York, NY, January 8, 2001 [cit. 2001-11-14]. Dostupný z: http://www.verity.com/press/2001/20010108.html.
25.ELAG. Integration Heterogeneous Resources [on line]. Prague, 6-8 June 2001 [cit. 2001-11-14]. Dostupný z: http://www.stk.cz/elag2001/ELAG2001.html.
26. HEIJTING, Inge. Interconnectivity and the Hybrid Library. Ikaros [online]. 1999, č. 10 [cit. 1999-11-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c10/ebsco.htm.
27. JONÁK, Zdeněk. Inteligence systémů zpracování textů. Ikaros [online]. 2000, č. 1 [ cit. 2000-01-05]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/2000/c01/isko/z_jonak.htm.
28. JONÁK, Zdeněk. Krize mezilidské komunikace v období komunikační a informační exploze. Ikaros [online]. 1999, č. 5 [cit. 1999-05-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c05/veda4.htm.
29. JONÁK, Zdeněk. Pojem "informace" ve světě sdíleného pojetí skutečnosti. Ikaros [online], 2000, č. 2 [cit. 2000-02-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/2000/c02/veda.htm.
30. JONÁK, Zdeněk. Pokles důvěry ve vědu jako důsledek změny paradigmatu vědy : důsledky změny paradigmatu v informační vědě. Část 1. Ikaros [online]. 1999, č. 2 [cit. 1999-02-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c02/veda.htm.
31. JONÁK, Zdeněk. Reflektuje teorie informace a komunikace dostatečně na zvýšený zájem společenských věd o semiotické a komunikační aspekty života? Ikaros [online]. 1999, č. 3 [cit. 1999-03-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c03/veda2.htm.
32. JONÁK, Zdeněk. Vztah komunikační a obsahové struktury literárního díla. Ikaros [online], 1999, č. 6 [cit. 1999-06-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c06/kom.htm.
33. KOCH, Traugott and BORELL, Mattias. Dublin Core Metadata Template [online]. Lund (Švédsko) : Lund universitetsbibliotek, 1997, last update 1997-08-20 [2000-04-10]. Dostupný z: http://www.lub.lu.se/metadata/DC_creator.html.
34. Metadata [online]. Bath (Anglie) : UKOLN, last updated 16-Feb-2000 [cit. 2000-04-10]. Dostupný z: http://www.ukoln.ac.uk/metadata/.
35. NEDLIB : Networked European Deposit Library [online]. Hague (Nizozemí) : Koninklijke Bibliotheek, c1998, last updated 11-Mar-2001 [cit. 2001-04-28]. Dostupný z: http://www.kb.nl/nedlib.
36. Networked European Deposit Library [online]. Hague (Nizozemí) : Koninklijke Bibliotheek, last upd. 11-Mar-2001 [cit. 2001-03-14]. Dostupný z: http://www.kb.nl/nedlib.
37. Nordic Countries URN-generator : provided by the Nordic Libraries [online]. Lund (Švédsko) : Lund universitetsbibliotek, 1997 [cit. 2000-04-10]. Dostupný z:http://www.lub.lu.se/cgi-bin/nmurn.pl.
38. The Nordic Metadata projects [online]. Helsinki (Finsko) : Helsinki University, 1996, last updated 21 February 2000 [cit. 2001-04-28]. Dostupný z: http://www.lib.helsinki.fi/meta.
39. OLSON, Nancy B. Cataloging Internet Resources [online]. Dublin (Ohio, USA) : OCLC, 1997 [cit. 2000-04-10]. Dostupný z: http://www.purl.org/oclc/cataloging-internet.
40. PAPÍK, Richard. Trendy v rozvoji informačních služeb. Ikaros [online]. 1999, č. 8 [cit. 1999-09-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c08/usti/usti_papik.htm.
41. Projects at the Royal Library in Stockholm, Sweden [online]. Stockholm : Royal Library, updated July 1, 1999 [cit. 2000-11-14]. Dostupný z: http://www.kb.se/ENG/projekt.htm.
42. Serial Item and Contribution Identifier [cit. 2000-11-14]. Dostupný z: http://sunsite.berkeley.edu/SICI/version2.html.
43. SICI Generator [cit. 2000-11-14]. Dostupný z: http://www.ep.cs.nott.ac.uk/~sgp/sicisend.html.
44. SVOBODA, Martin. Elektronické publikování. Ikaros [online], 1999, č. 3 [cit. 1999-03-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c03/elpubl98/index.htm.
45. The Nordic Metadata projects [online]. Helsinki (Finsko) : Helsinki University Library, 1996, last updated 21-Feb-2000 [cit. 2001-04-28]. Dostupný z: http://www.lib.helsinki.fi/meta.
46. TKAČÍKOVÁ, Daniela. Když se řekne digitální knihovna ... Ikaros [online], 1999, č. 8 [cit. 1999-09-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c08/usti/usti_tkacikova.htm.
47. UHLÍŘ, Zdeněk. "Computing in Humanities", čili: Táhneme, anebo jsme vlečeni? Ikaros [online], 1999, č. 11 [cit. 1999-12-01]. Dostupný z: http://ikaros.ff.cuni.cz/ikaros/1999/c11/computing.htm .
48. Uniform Resource Names (urn) Charter [online]. Reston (VA, USA) : IETF, last modified 03-Jun-99 [cit. 2000-04-10]. Dostupný z: http://www.ietf.org/html.charters/urn-charter.html.
49. VOJTÁŠEK, Filip. Služby iDNES se rozrostly o regionálně členěný katalog odkazů. Ikaros [online]. 2001, č. 4 [cit. 2001-02-04]. Dostupný z: http://ikaros.ff.cuni.cz/2001/c04/welcome.htm.
50. ŽABIČKA, Petr. Dublin Core - metadata pro popis elektronických dokumentů. Předneseno na konferenci DATASEM 2000, konané 21. až 24. října 2000 v Brně. Dostupný z: http://webarchiv.nkp.cz/datasem2000.pdf.
51. ANL FULL - Plnotextové vyhledávání v článcích z tisku. Topic system (experiment) [online]. Dostupný z: http://full.nkp.cz.
52. Báze ANL [online]. Dostupný z: http://sigma.nkp.cz/F/3TLEBXX6XQ7FSA6637D7F4YBYMMSN271ASJC5YTXBJBXGH66CY-31565?func=file&file_name=find-a&local_base=anl .
53. Metodika popisu článků ve formátu UNIMARC [online]. Dostupný z: http://nkpnew.2b.cz/pages/page.php3?page=oazp_popis1.htm .
54. Seriály (periodika) a analytický popis (články) v České republice, plné texty Propojení bibliografických záznamů s plnými texty [online]. Dostupný z: http://nkpnew.2b.cz/pages/page.php3?page=oazp_anal_popis.htm.
55. [Výsledky práce společnosti ANOPRESS, s.r. o. a informace o veřejné dražbě na adrese, online]. Dostupný z: http:/www.anopress.cz.
Při formulaci dotazů je možno využít operátory, vyhledávání v polích,
zkracování selekčních údajů apod. Ve všech databázích jsou k dispozici seznamy
selekčních polí formální a zejména věcné povahy . Velmi důležitým údajem je typ
dokumentu (nekrology, recenze divadelních her, oper apod.).
Směry a nástroje pro integraci heterogenních zdrojů byly nosným tématem semináře ELAG, který se konal v r. 2001 v Praze. Zmíníme se o několika tématech diskutovaných na tomto semináři a o některých projektech zde referovaných. Tyto otázky jsou na pořadu dne i v ČR.
Projekty
Projekt Renardus: Akademický tematický portál konsorcia 12-ti institucí. Řešen v rámci pětiletého rámcového programu EU "Technologie pro informační společnost". Renardus má umožňovat paralelní pohyb uživatele po tematických portálech (metadata DC, Z39.50, DDC).
Architektura pro britskou národní digitální knihovnu UK DNER (Distributed National Electronic Resource). Cíl: Národní digititální knihovna pro vyšší a další vzdělávání, distribuovaný zdroj informací pro vzdělávání a výzkum, řízený soubor zdrojů, heterogenní povahy. Bibliografická data, obrázky, texty, video, dostupnost místní i dálková. Fondy jsou typicky ve formě sbírek: primárních dat, sekundárních dat (tématické portály, knihovní katalogy, databáze) (Z39.5, portály, Bath profil, XML) Nástroje integrace heterogenních dat: XML, identifikace zdrojů, propojování, protokoly, digitální knihovny DC (Dublin Core) Formát metadat pro popis webovských informačních zdrojů - formát definovaný na základě mezinárodního konzensu - obsahuje 15 prvků k identifikaci zdroje.XML (eXtensible Markup Language)
Jazyk XML je, podobně jako jazyk HTML, prostředek sloužící k zapsání strukturovaného textu , zvláště pak textu určeného k šíření v prostoru www. XML je formát textový, tzn., že dokument je možno vytvářet, přenášet a zpracovávat na libovolná data, jakýmkoli počítačovým systémem, jsou vyřešeny jazykové a kódové problémy. XML odděluje popis struktury dat od jejich prezentace (pomocí tzv. style sheetů). To umožňuje snadnou konverzi do jiných formátů, možnost prezentace dat různými způsoby (HTML, postcript, UNIMARC, textový formát apod.). Každý dokument má definovanou svoji strukturu prostřednictvím tzv. DTD (Document Type Definition). Tato DTD může být unikátní pro každý dokument, ale může být také společná pro celou řadu dokumentů. Velký potenciál XML se skrývá v novém způsobu odkazování (oběma směry, na více dokumentů najednou či dokonce v rámci hierarchické struktury) pomocí speciálních jazyků XLink, XPointer a XPath. Totéž lze říci o stylovém jazyku XSL, který doplňuje a nahrazu je tzv. kas kádové styly (CSS)Oblasti potenciálního využití XML jsou široké. Otevírá možnosti v klasickém i elektronickém publikování.
RDF (Resource Description Framework) Poskytuje základ pro popis v různých aplikačních doménách. Jako modelovací jazyk používá entity, atributy, vztahy. Propojování informačních zdrojů FRBR Functional Requirements for Bibliographic Records - relace mezi Dílem, Vyjádřením díla, Provedením díla a Exemplářem díla (Work, Expression, Manifestation, Item). Propojování se zavádí komerčně: databáze statických odkazů, z abstraktových a indexových databází k plnému textu, z citace v plném textu na plný text, z OPAC k časopisu a jeho obsahu a odtud k plnému textu, většina linků je statických pro konkrétní případy předem budovaná. Dynamické linky jsou budovány následně, v době potřeby, jsou pravděpodobnostní. Propojování pomocí URL, PURL, URN a DOI. SFX (Special Effects) je databáze, která na základě jednotně stavěné identifikace dokumentu (Open URL) odvozené od metadat dokumentu a podle práv uživatele (context sensitive) nabízí další služby, jejichž dostupnost má uživatel zajištěnu. Práva uživatele musí SFX zaznamenat ve zvláštní databázi předem nastavené a podle toho bude nabízet služby dostupné obsluhovanému uživateli. Nabízené služby závisí též od obsahu OpenURL.V Open URL se může využít i identifikace dokumentů pomocí DOI, kdy SFX je schopen se spojit s databází CrossRef a převést DOI na OpenURL s bibliografickými údaji. Open URL vytváří ze svých metadat řada předních světových poskytovatelů on-line zdrojů.Metalib a SFX. Metalib je multivyhledávač, který vyhledává v několika
zdrojích najednou a to pomocí protokolu Z39.50, Aleph proprietary protocol, Http
protokol přizpůsobený na vybrané cíle. Metalib obsahuje Knowledge base ( seznam
zdrojů, které může prohledávat), nástroje pro údržbu této knowledge base, a
vyhledávací a presentační SW. Zdroje dat mohou doplňovat svá data tak, že z
metadatat formují tzv. OpenURL.
JSTOR - Journal Storage
Mezinárodní nevýdělečné konsorcium zaměřené na digitalizaci a zpřístupnění klíčových amerických humanitních vědeckých časopisů (v současnosti je k dispozici databáze 117 časopisů z Arts & Science I Collection, obsahující všechny články od prvního čísla časopisu, s retrospektivou do minulého století, až po současnost).Zabezpečení vědy a výzkumu v humanitních oborech základními informačními zdroji -
- celonárodní licence na on-line přístup do fulltextové databáze ProQuest 5000 (plné texty 5000 humanitně orientovaných časopisů) a bibliografické databáze PCI Web (Periodicals Contents Index). Databáze: Arts, Law, Humanities, Women, Social Sciences Plus Text, Education Complete, Career and Technical Education, Medical Library, Health, Pharmace utical News Index, Applied Science and Technology, Computing, Telecommunications, Religion, ABI/Inform Global, European Business, Asian Business, Accounting and Tax, Banking Information Source.
Zpřístupnění plnotextových databází odborných zahraničních periodik na
základě programu
Open Society Institute EIFL-Direct - plošná multilicence.
Plné texty celkem 3.300 časopisů od r. 1990 a další informační zdroje (abstrakty, zpravodajství, příručky) především z oblasti sociálních a humanitních věd (od EBSCO Publishing, jednoho z předních světových dodavatelů el. a tištěných časopisů), nabízené ve 4 dílčích databázích:
- Academic Search Elite (společenské a humanitní vědy) - Business Source Premier (ekonomie, finance, management, účetnictví, mezinárodní obchod)OCLC FirstSearch Service
Služba OCLC FirstSearch s přístupem k plným textům OCLC Base Package with Full Text od organizace OCLC. Služba FirstSearch kombinuje funkce souborných katalogů, meziknihovních služeb, dodávání dokumentů a přístupu k elektronickým plným textům dokumentů. Kromě souborného katalogu (WorldCat) je zahrnut přístup do 12 dalších databází: ArticleFirst (bibliografické citace článků z 13.000 periodik), ContentFirst (seznamy obsahů periodik), NetFirst (bibliografické údaje o odborných zdrojích na Internetu, včetně abstraktů a klasifikace), PapersFirst (referáty ze světových konferencí, kongresů, sympozií, výstav a workshopů od 1983), ProceedingsFirst (seznamy obsahů sborníků z vědeckých konferencí), UnionLists (souborný katalog periodik s uvedenými lokacemi), WilsonSelect (plné texty článků z 800 periodik), WorldAlmanac MEDLINE (medicínská informace), ERIC (bibliografie literatury z oblasti vzdělávání) a další.Některé zpravodajské servery na českém Internetu :
České noviny
http://ctk.ceskenoviny.cz/ ,
iDNES http://zpravy.idnes.cz/ ,
Lidové noviny
http://www.lidovky.cz/ ,
iHNed http://www.ihned.cz/ ,
Právo http://www.pravo.cz/ .
Server iDNES nabizí služby v podobě regionálně členěného katalogu odkazů, částečně funguje jako předmětový katalog odkazů. Na rozdíl od Seznamu.cz, Atlasu nebo Centra.cz jsou odkazy v Klikni.cz uspořádány do 14 regionálních sekcí odpovídajících současnému územnímu uspořádání České republiky.
Některé vyhledávače na českém webu:
Seznam http://www.seznam.cz/ ,
Centrum http://www.centrum.cz/ ,
Redbox http://www.redbox.cz/ ,
Quick http://www.quick.cz/ ,
Current Contents, abstrakty, citace, plné texty
AVČR - Časopisy vydávané Akademií věd České republiky, http://www.lib.cas.cz/knav/journals/Casopisy_AVCR.htm . Některé časopisy jsou vybaveny abstraktem a plným textem, někde pouze obsahy časopisů.
Nakladatelství Karolinum, Nakladatelství Univerzity Karlovy - vydávání učebních textů, vědeckých monografií, sborníků vědeckých prací, slovníků a vědeckých časopisů - current contents. http://www.cuni.cz/cuni/uz/nk/ .
Odborná knihovnická periodika
Národní knihovna. Knihovnická revue, http://full.nkp.cz/nkkr/NKKR.html (formát pdf a html pro rok 1999, 2000 a 2001 - webovská prezentace periodika v rámci Projektu propojení analytických záznamů s plnými texty), ostatní čísla plnotextově přístupná na serveru FULL.NKP.CZ a www.anopress.cz .Ikaros, elektronický časopis o informační společnosti,
http://ikaros.ff.cuni.cz
Daidalos, informační server pro knihovníky (činnost ukončena),
http://daidalos.ff.cuni.cz/
Bulletin SKIP,
http://skip.nkp.cz/Bulletin/Bulletin.htm
U nás, http://www.svkhk.cz/unas/
.
V rámci Parlamentní knihovny se buduje systém, ve kterém jsou zpřístupněna v plné formě parlamentária. Digitální knihovna "Český parlament", http://www.psp.cz/eknih/ .
Dokumenty Senátu, http://www.senat.cz/dokumenty/index.htm .Informační agentury
Albertina icomeNewton I.T.
Elektronická výstřižková služba, elektronický archív novin a časopisů
celostátních a regionálních,
http://www.newtonit.cz/
Neumožňuje přímý přístup do celé databanky. Buduje následující archívy:
Deník Právo - http://www.pravo.cz
Deník Pražské slovo - http://zn.newton.cz
Časopis 100+1 zahraniční zajímavost -
http://stoplusjedna.newton.cz
Elektronický archiv deníku Právo -
http://pravo.newtonit.cz
Elektronický archiv deníku MF Dnes -
http://mfdnes.newtonit.cz
Elektronický archiv týdeníku Týden -
http://tyden.newtonit.cz
Elektronický archiv týdeníku The Prague Post-
http://praguepost.newtonit.cz
Elektronický archiv týdeníku Respekt -
http://respekt.newton.cz
Týdeník Profit - http://www.profit.cz .
On-line databanka novin a časopisů celostátních a regionálních, monitoring na zakázku, vědomostní databáze, http://www.anopress.cz/ .
Anopress, s.r.o. umožňuje on-line přístup do databanky plných textů TamTam, na jejíž bázi poskytuje následné služby. Společnost zpřístupňuje informace zákazníkovi na dané téma. Anopress s.r.o. umožňuje přístup do databanky novin on-line na základě licenčních smluv a umožňuje nákup celých titulů periodik. Společnost Anopress je výhradním zpracovatelem elektronické podoby většiny českých regionálních titulů (51 titulů nakladatelství Bohemia). Pro zpřístupnění plných textů ve veřejných knihovnách bylo založeno Konzorcium Anopress. Společnost je výhradním zástupcem slovenské firmy SLOVAKIA ONLINE v ČR, která zpracovává elektronickou podobu slovenských tištěných médii. Kromě mediální části obsahuje databanka TAMTAM i část vědomostní, v níž jsou k dispozici pro fulltextové vyhledávání různé encyklopedie, příručky a další knihy referenčního charakteru. Agentura od roku 1998 průběžně vytváří rozsáhlou databanku, která v současné době obsahuje texty článků a zpráv z devíti celostátních deníků a z téměř 80ti deníků regionálních a dále i textové záznamy zpravodajských, publicistických a diskusních pořadů rozhlasu a televize.Související projekty, metody a nástroje, související se zpřístupněním plných textů
WebArchiv je vytvářen v rámci programového projektu výzkumu a vývoje "Registrace, ochrana a zpřístupnění domácích elektronických zdrojů v síti Internet". Jeho cílem je připravit podmínky pro zpracování české národní bibliografie elektronických zdrojů, se zaměřením zejména na zdroje dálkově přístupné. Do češtiny byla přeložena nejnovější verze standardu Dublin Core Metadata Element Set, Version 1.1 proběhla lokalizace metadatového formuláře převzatého od Helsinské univerzitní knihovny z projektu Nordic Metadata.Jednotná informační brána
Programový projekt Ministerstva kultury ČR "Jednotná informační brána pro hybridní knihovny" - řeší otázku jednotného uživatelského rozhraní pro hybridní knihovny. Takovou knihovnou je Metalib. Databáze ALEPH NK jsou jedním ze zdrojů této knihovny.
Komunikace v Metalib je na základě protokolu Z39.50 nebo HTTP. Metoda konspektu jako nástroj popisu fondů má přispět k realizaci této brány. Základem metody základem je popis dle věcného třídění na několika úrovních. První obsahuje 24 tématických skupin, druhá 500 kategorií, které se dále člení na 4 000 témat. Vazba na jednotnou informační bránu: výběr věcného oboru v Metalibu podle členění tématických skupin. Při věcném popisu báze ANL se užívají také předmětové kategorie (od r. 1994) určené pro zařazení článků do hrubých oborů či témat pro zpřehlednění báze. Domníváme se, že tyto kategorie budou podrobnější než ty, aplikované v metodě konspektu. Podobně topiky na serveru FULL.NKP.CZ používají tři úrovně definice - tématická oblast, skupin témat, detailní témata.
Propojování - Metalib a SFX
SFX je standard pro propojení dokumentů a je využíván v Metalib k vytváření vazeb. V Metalib je statický způsob propojení nahrazován dynamickým propojováním založeném na open URL.
Autorskoprávní a legislativně právní problematika zpřístupňování elektronických dokumentů - v ČR je třeba aktualizovat zákon o povinném výtisku seriálových publikací, event. autorský zákon. Povinný výtisk elektronických publikací je předpokladem jejich uchovávání a zpřístupnění.Dále je třeba v budoucnu uzavírat dohody mezi knihovnami a příslušnými nakladateli a vydavateli, které se budou týkat jednak zpřístupnění elektronických dokumentů, jednak spolupráce.Stručný popis produktů TamTam:
Popis řešení
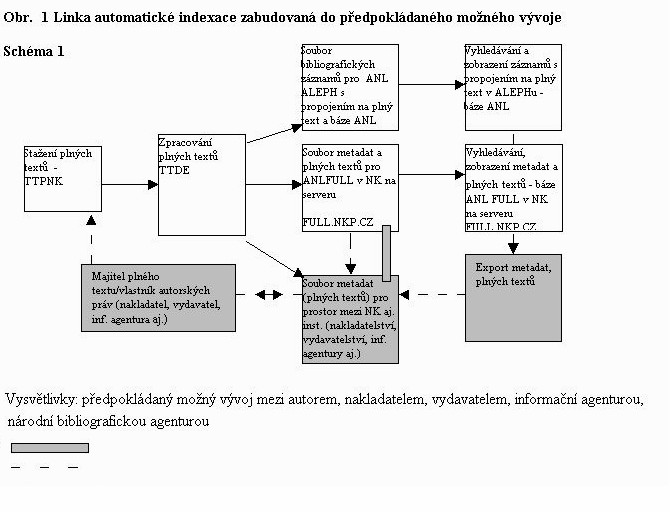
Pro optimalizaci integrace a sprá vy heterogenních dat souborné databáze kooperačního vyvinula česká firma Anopress na podkladě analýzy a funkčního zadání návrh speciální technologie - linky automatického získávání plných textů, indexace bibliografických záznamů a plných textů, propojování záznamů na plné texty a jejich zpřístupnění. Řešení je progresivní a odpovídá nejnovějším trendům v této oblasti, je podpořeno kvalitním technickým a programovým vybavením. Jednotlivé moduly lze použít i samostatně. V rámci experimentu v r. 2001 byla doladěna linka automatického zpracování ve všech jejich fázích a uvedena od května t. r. do provozu. V roce 2000 vyvinutý jednoduchý formulář byl rozšířen a doplněn kromě jiného zejména o pole věcného popisu a pole pro vazbu k propojení analytického záznamu se zdrojovým dokumentem v bázi NKC (vazba LKR). Automaticky je generována URL adresa, SICI, "provizorní" URN, které sleduje filozofii a strukturu stanovenou pro tvorbu URN. Automaticky lze generovat klíčová slova a převádět do formuláře. Na výstupu procesu zpracování byla zabudována funkce kódování výsledného souboru záznamů v Ansel, UNICODu a UTF-8. Poté je záznam odeslán do určeného adresáře na serveru FULL.NKP.CZ. Programovou aplikací vyvinutou v NK je soubor naimportován do báze ANL (ALEPH) a zaindexován a zpřístupněn v systému TOPIC na serveru FULL.NKP.CZ v podobě plného textu vybaveného metadaty (UNIMARC a aplikace Dublin Core v podobě HTML, XHTML, XML v kvalifikované a nekvalifikované formě). Vyhledání je možno z plného textu, z metadat v něm uložených (vyhledávání pomocí polí, formulářů,topiků a rejstříků). Zobrazení je možno pomocí tří uživatelských formátů. Vyřešen je také tisk jak seznamu vyhledaných článků, tak tisk jednotlivých plných textů. Export metadat a plných textů bude řešen v roce 2002. V roce 2001 byla vyvinuta aplikace pro registraci, autentifikaci a přihlášení externích uživatelů prozatím na dobu 7 dnů. Otáz ky zpřístupnění externím uživatelům závisí na vyřešení legislativně právních otázek event. ekonomických. Externím uživatelů jsou běžně zpřístupňována metadata. Plné texty a metadata jsou zpřístupňována interním uživatelům NK. Linka automatické indexace je použitelná po úpravě vstupním filtrem i na data existující v jiné databázi, event. v komunikaci mezi autorem, nakladatelstvím, bibliografickou agenturou a naopak. Předpokládá však do jisté úrovně strukturovaný vstupní text, ze kterého data mohou být extrahována. V této struktuře mohou být zachyceny údaje nejen jmenné povyhy (autor apod.), ale i povahy věcné (klíčová slova, abstrakt).Ty je potom možno převést pomocí vstupního filtru do linky automatické indexace k dalšímu zpracování. V neposlední řadě je možnost automatického zpracování závislá na způsobu organizace práce s těmito texty a jejich umístění v eventuelní databázi. Automatická indexace věcná je závislá na vytvoření tezaurů řízených heslářů s vazbou na klasifikační notaci v podobě MDT či UDC oproti kterým je porovnáván plný text a na základě tohoto porovnání přidělovány příslušné věcné termíny.B. 1. 1 Linka automatické indexace
Údaje o článku jsou pomocí speciálních maker vkládány v Anopressu do hlavičky textu dokumentu a takto vybavené textové dokumenty jsou ukládány a indexovány a zpřístupňovány v databázi TAMTAM (TOPIC). Řešení spočívá ve speciální aplikaci v praxi již používané technologie firmy na získávání a zpřístupňování plných textů pro NK - TAMTAM Profesional NK (TTPNK ) - TamTam NK_special. Pomocí této technologie, aplikace se stahují plné texty článků z Internetu z báze TAMTAM, založené plnotextovém pojmovém vyhledávání systému TOPIC. Je možno stahovat více článků najednou na základě tématu, názvu článku, názvu zdrojového dokumentu aj. údajů (pro stahování je možné využít i verzi TAMTAM Standard - TTS). Pracovník oddělení analytického zpracování NK nejprve vybere a vyhledá příslušné články ke zpracování v této databázi. Poté proběhne stažení vybraných článků na počítač příslušného pracovníka v podobě komprimovaného souboru. Po jeho dekompresi je text článku naimportován do příslušného adresáře. Po otevření formuláře ke zpracování se objeví v levém části formuláře seznam názvů článků. Po kliknutí na článku se automaticky objeví údaje o článku, které jsou obsaženy v jeho hlavičce ve formuláři a příslušných hlavičkách. Po kontrole takto extrahovaných údajů z plného textu se doplňují další bibliografická metadata zejména věcné povahy. Poté je soubor zpracovaných článků odeslán. Tímto způsobem jsou zpracovávány všechny celostátní deníky a některé odborné časopisy.Pro pro vlastní automatickou indexaci článků a plných textů - pro vytváření bibliografických záznamů v UNIMARCU a metadat Dublin Core v různých jeho aplikacích v HTML, XHTML, XML na základě údajů uložených v plných textech je určena technologie TAMTAM Data Extractor.
Údaje jsou extrahovány z plného textu a na jejich základě je generováno 5 hlaviček (headers). Data jsou zpracovávána pomocí pomocí rozšířeného formuláře pro editaci.
Následuje odeslání záznamů pomocí voby "odeslat" na dolní liště, import do Alephu (program vyvinutý v NK), import na server FULL.NKP.CZ
Pro indexaci dat do fulltextové databáze (ANL FULL) v NK byl vyvinut program MKINDEX Pro vyhledávání v datech ve fulltextové databázi jsou vyvinuty formuláře pro vyhledávání jednoduché, pokročilé, pokročilé s tématy. Vyhledávání probíhá v systému TOPIC (Search 97) a definice formulářů vychází z jeho filozofie. Pro propojení plných textů s bibliografickými záznamy v systému ALEPH (doplnění URL adres do záznamů ) byl vytvořen skript MKDOC.PHP. Propojení probíhá ne základě dynamicky generovaného odkazu na dokument. Program vyhledá požadovaný dokument dle identifikace (identifikační číslo),provede statistiku a kontrolu autorizace a na jejím základě zobrazuje plný text, abstrakt a citaci dokumentu v rámci databáze ANL FULL.Zpracování článku v lince automatické indexace ilustruje následující sekvence obrázků:
Obr. A, Obr. B, Obr. C, Obr. D, Obr. E, Obr. F, Obr. G, Obr. H, Obr. I
Celý proces obecně ilustruje schéma na Obr. 1.
Plný text je funkční v kódu v kódu CP 1250.
Inspirací a do jisté míry vzorem pro koncipování báze ANL FULL je databáze ProQuest. TOPIC (pojmově orientovaný vyhledávací systém, concept based retrieval) je systém třetí generace založený na následujících principech: rozklad pojmu na podpojmy, vážení jednotlivých podpojmů (větví pojmového stromu), neostré vyhodnocování dotazů.Nabízí se zde jistá formální analogie k hierarchickému selekčnímu jazyku systémové notace MDT.
Je však třeba zdůraznit, že topiky jsou tvořeny podle skutečnosti, MDT je víceméně taxativní systém jednotlivých oborů, nikoli témat. Proto je třeba k definici topiků přistupovat svébytně.
V oddělení analytického zpracování při věcném popisu článků se používají k indexaci hrubých témat a podtémat předmětové kategorie, které připomínají svou podstatou topiky, resp. témata a skupiny témat v systému TOPIC v databázi Anopress. Je však třeba je sladit obsahově.B.1.2.1 Charakteristika serveru FULL.NKP.CZ
Server FULL.NKP.CZ je určen primárně ke zpřístupňování plnotextových dokumentů, v současné fázi zejména těch, které jsou obsaženy v periodicky vydávaných dokumentech české provenience.
B.1.2.1.1 Základní členění stránek - základní a dílčí nabídky
Stránky jsou tvořeny horní pruhem a základní částí (hlavním prostorem). Horní pruh (frame) je přístupný stále, obsahuje v horní části dynamické rozbalovací menu s jednotlivými nabídkami základních a dílčích funkcí. V základní části se zobrazují požadované funkce. Obecné (základní) informace
Charakteristika db (projekty, charakteristika serveru, charakteristika
báze ANL FULL)
Další databáze (databáze NK - charakteristika báze ANL)
Periodika na WWW (volně dostupná periodika na www)
Další informace (seriály-periodika a analytický popis-články v České
republice)
Vstup do db (ANL FULL)
Jak se zaregistrovat (komentář)
Registrace (formulář)
Přihlášení (formulář)
Vyhledání (ANL FULL)
Jak vyhledávat (metodika)
Formuláře
Rejstříky
B.1.2.1.2 Charakteristika databáze ANL FULL (obsah, zdroje)
Databáze ANL FULL - fulltextové vyhledávání ve vybraných článcích z novin a časopisů zatím s retrospektivou od r. 1997. Databáze je provozována na na serveru full.nkp.cz v systému TOPIC. Plné texty jsou vybaveny citací (bibliografický popis, resp.metadata), automaticky tvořeným souhrnem (začátek článku).B.1.2.1.3 Další databáze (ANL)
Souborná databáze báze ANL obsahuje bibliografické záznamy vybraných článků novin, časopisů a sborníků zpracovávaných v rámci Kooperačního systému článkové bibliografie (KOSABI). Databáze vychází jako řada České národní bibliografie. Vyhledávání je možné z údajů bibliografického popisu. Některé záznamy báze jsou propojeny na plné texty umístěné v bázi ANL FULL. Báze ANL obsahuje navíc linky na plné texty některých periodik a plná znění některých zákonů volně dostupných na na WWW (odborná knihovnická periodika - Ikaros, U nás, Bulletin SKIP, Daidalos), další odborová periodika (Lesnická práce, Psychiatri e, Psychologie dnes, Vesmír, Harmonie, Collection of Czechoslovak Chemical Communications, Veřejná správa). K článkům pojednávajícím o zákonech jsou připojována plná znění zákonů.Výběr článků ke zpracování (viz výše).
Obsah:
- v NK ČR
- ve spolupracujících institucích.
B.1.2.1.4 Periodika na WWW - Portál
Nabídka volně přístupných periodik na Internetu se dále bude doplňovat, event. jejich uspořádání měnit. Nejsou zde zahrnuta periodika firemní, inzertní, bulvární, propagující hnutí potlačující lidská práva, sportovní, zpravodajská (zprávy z tiskových agentur bez dalšího kontextu) aj. periodika efemérní povahy.Dílčí nabídky:
Oborová periodika jsou členěna do skupin a v rámci nich do jednotlivých oborů a oblastí:
Kultura a umění
Další zdroje periodik dostupných na WWW (některé informační agentury,
zpravodajské servery, nakladatelství, vyhledavače)
Takto zpřístupněná volně dostupná periodika jsou struktorována do přehledné formy portálu na úrovni krajské, tématické a isntitucionální.
B.1.2.1.5 Jak se zaregistrovat (komentář k registraci v databázi ANL FULL)
Bibliografické údaje o článcích, resp. metadata a plné texty jsou k dospozici čtenářům Národní knihovny. Pro externí uživatele jsou běžně k dispozici pouze bibliografické údaje o článcích. Tito uživatelé se musí pro získání plného textu zaregistrovat pomocí formuláře v nabídce Registrace. Po vyplnění povinných údajů bude těmto uživatelům zasláno e-mailem potvrzení registrace s aktivačním odkazem a heslem - po odeslání tohoto odkazu je registrace aktivována a prostřednictvím přiděleného hesla zajištěn bezplatný zkušební přístup na dobu sedmi dnů. Rutinní zpřístupňování plných textů bude možné po vyřešení autorskoprávních, popř. ekonomických otázek souvisejících se zpřístupňováním plných textů.Nabídka Přihlášení slouží k autentifikaci registrovaného uživatele. Ve formuláři pro přihlášení je třeba vyplnit jméno a přidělené heslo.
B.1.2.1.6 Jak vyhledávat
Báze ANL FULL obsahuje jak bibliografické popis v různé míře podrobnosti podle vývoje systému, tak plný text, přičemž obě tyto části jsou indexovány a lze z nich paralelně vyhledávat a docílit tím větší míru relevance výsledku vyhledávání k položenému dotazu.Vyhledávat lze též pomocí rejstříků. Systém TOPIC navíc umožňuje pojmové vyhledávání podle témat, resp. topiků (viz dále). TOPIC umožňuje velmi sofistikované kladení dotazů vyžadující určitou zkušenost. Na druhé straně je možné položit dotaz velmi jednoduchým způsobem.
Formuláře - tři základní formuláře podle pokročilosti vyhledávání - základní, rozšířený, rozšířený s tématy, resp. s topiky (viz dále).
Rejstříky - nadefinováno 17 rejstříků, podoba rejstříků se bude dále optimalizovat (viz dále).
Dotazy - druhy dotazů se liší náročností formulace a možností ovlivnit výsledek vyhledávání (viz dále).
Prostý dotazFormulářový dotaz
Obsahuje kromě možnosti pro zadání hledaného slova nebo fráze jako u
prostého dotazu i pole pro zadání podmínek pro jednotlivé položky strukturované
části textové databáze. Jde o rozšíření prostého dotazu.
Pole
Pole dotaz, resp. text dotazu - obsaženo ve všech formulářích.
Implicitní pole - ob sažena v rozšířeném formuláři a v rozšířeném formuláři s tématy .
Vazby mezi polem dotaz, dalšími poli a tématy
Způsoby zobrazení seznamu výsledků (názvů vyhledaných článků) - viz dále.
V záhlaví seznamu výsledků uveden počet vyhledaných článků, možnost listovat v seznamu výsledků.
Seznam výsledků (názvů vyhledaných článků):Zobrazení údajů o článku viz dále.
B.1.2.1.6.1 Vyhledávání
Vyhledání probíhá fulltextovou formou, tj. z plného znění jednotlivých dokumentů a z jejich citace, resp. metadat, resp. bibliografického popisu. Systém rozeznává pádové koncovky podstatných a přídavných jmen. Lze vyhledávat podle jednoduchého slova nebo fráze. U rozšířeného formuláře a u rozšířeného formuláře s tématy lze nastavit (ve spodní části formuláře) pro implicitní pole formuláře vyhledávání podle výskytu řetězce kdekoli v poli pomocí operátoru <contains>. Pokud je vy žadováno přesné zadání i porovnání celého řetězce použijeme =. Tyto operátory lze zapsat take přímo do pole dotaz, resp. hledat v textu. Operátor <contains> lze v tomto případě zapsat jednoduše jako #. V tomto případě nastavení operátorů nemá vliv při hledání z polí pomocí návěští a při použití různých konvencí (savored, *, atd.). Doporučujeme však v případě nejistoty nastavení <contains>.B.1.2.1.6.2 Formuláře
Jsou k dispozici tři typy formulářů vzhledem k pokročilosti způsobu vyhledávání a možnostem kombinací při vyhledávání. Jednotlivé funkce formulářů a metodika zápisu údajů pro vyhledávání viz dále. Základní formulář
Rozšířený formulář
Nabídky:
Obsahuje stejné nabídky jako základní formulář, navíc pak vyhledávání podle imlicitních polích ve struktuře formuláře. Je možno zvolit, zda vyhledávat v těchto implicitních polích způsobem <contains> nebo způsobem =. Pro seznam výsledků je možno navíc navolit oproti základnímu formuláři skóre relevance, od které zobrazovat články, zobrazit určitý počet článků na stránku, dále třídit dle skóre relevance, názvu, zdroje,data vydání, stran, a to sestupně či vzestupně. Hledat v textu - odpovídá poli Dotaz v základní formuláři (f ormulace dotazu)Implicitní pole:
název, autor (s nabídkami pro jednotlivé údaje)
číselné údaje (s nabídkami pro jednotlivé údaje)
předmět (s nabídkami pro jednotlivé údaje)
další nabídky: typ článku (s nabídkami pro jednotlivé typy článků)
zdrojový dokument (s nabídkami zdrojových dokumentů)
Způsob vyhledání řetězců (v implicitních polích):
< contains> (postačí výskyt řetězce v poli)Typ seznamu výsledků (článků):
jednoduchý (pouze název s nabídkou zobrazovacích formátů)Rozšířený formulář s tématy
Nabídky:
Tento formulář má stejné nabídky pro vyhledávání jako rozšířený formulář, umožňuje vyhledávat navíc podle témat, resp. topiků, resp. dotazů. Pro bázi ANL FULL jsou nadefinovány některé topiky, rozdělené do tří úrovní.Topik slouží k tomu, že hledaný výraz vyplněný do textu dotazu a různě zpřesňovaný je navíc upřesněn topikem, tj. tématem. Tři úrovně topiků viz dále 7.3.3. Např. hledáme-li v bázi výraz hvězdy, výsledek obsahuje několik tisíc dokumentů. Specifikujeme-li tento výraz pro vyhledávání v rámci astronomie, najdeme pouze několik set dokumentů.
B.1.2.1.6.3 Metodika vyhledávání
Uživatel zvolí typ vyhledávacího formuláře popř. změní jeho implicitní parametry. Vlastní dotaz potom je možné zadat několika způsoby .
B.1.2.1.6.3.1 Pole dotaz, resp. text dotazu
Nejjednodušší dotaz tvoří jediné slovo, fráze.Pro zadávání složitějších nebo víceslovných dotazů je možno použít logické operátory (and, or, not a další), případně další konvence,např. zástupné znaky (wildcards) - viz dále bod Př.1-9. Uvedením návěští se vyhledávání omezuje na příslušné pole - Př. 10-12 .
Základní operátory:
and - v poli jsou osbaženy všechny hledané výrazyKonvence pro všechny formuláře - pole dotaz, resp. text dotazu
Př. 1
hvězdy
Vyhledají se dokumenty, které obsahují různé gramatické tvary zadaného slova
(hvězdy, hvězdám...).
Př. 2
hvězdy, asteroidy, planetky
Vyhledá dokumenty, které obsahují různé gramatické tvary slov "hvězdy" nebo
"asterioidy" nebo "komety" (čárky lze nahradit operátorem or nebo <accrue>,
který je přesnější).
Př.: 3
(hvězdy, asteriody) and komety
Vyhledá dokumenty, které obsahují různé gramatické tvary slov "hvědy" nebo
"asteroidy" a zároveň s nimi nebo některými z nich i slovo "komety".
Př.: 4
(hvězdy and asteriody) not komety
Vyhledá dokumenty, které obsahují různé gramatické tvary slov "hvězdy" i
"asteriody" a zároveň neobsahují slovo "komety".
Př.: 5
komety <near> kolize
Vyhledá dokumenty, které zároveň obsahují různé gramatické tvary slov
"komety" i "kolize", a seřadí je podle textové vzdálenosti mezi těmito
slovy.
Př.: 6
"meteorický roj" or "padající hvězdy" .
Vyhledá dokumenty, které obsahují různé gramatické tvary frází "meteorický roj"
nebo "padající hvězdy".
Př.: 7
meteo*
Hvězdičková konvence: Vyhledá dokumenty, které obsahují slova začínající na
"meteo" (meteor, meteorický, apod.).
Př.: 8
*stvo
Hvězdičková konvence: Vyhledá dokumenty, které obsahují slova končící na
"stvo" (družstvo, mužstvo, apod.) .
Př.: 9
??běr
Otazníková konvence: Vyhledá dokumenty, které obsahují slova končící na
"běr" a sestávající z pěti znaků (výběr, záběr, apod.).
Návěští pro všechny formuláře (vyhledávání v polích)
Př.: 10
Data
dat <contains> 8.10.2001
dat# 8.10.2001
dat=8.10.2001
Vyhledá všechny dokumenty vydané v tomto dni.
Pozn.: Datum vydání lze jednodušeji navolit v nabídce období od do ve všech
formulářích. Zde je možno označit den či interval.
dac=29.10.2001
dac <contains> 29.10.2001
dat#29.10.2001
Př.:11
zdr=Respekt and naz=Rafinovaný odraz skutečnosti
src=Respekt and ti=Rafinovaný odraz skutečnosti
dc.source=Respekt and dc.title=Rafinovaný odraz skutečnosti
Př. 12
zdr <contains>Respekt and naz <contains>odraz
src<contains>Respekt and ti<contains>odraz
dc.source<contains>Respekt and dc.title <contains>odraz
Operátor <contains> lze nahradit #:
zdr#Respekt and naz#odraz
src#Respekt and ti#odraz
dc.source#Respekt and dc.title#odraz
Vyhledá dokumenty z názvu obsahující slovo "Respekt" a z názvu článku obsahující slovo "odraz" .
Tabulka návěští a prvky Dublin Core a Anl Core aplikované v bázi ANL FULL viz Charakteristika databáze.
Je-li případě tečkové konvence s dc (Dublin Core) použita ještě tečková konvence s anl, používá se konvence s anl (Anl Core) - Dublin Core není takto jemně definován nebo TOPIC v současné verzi systému toto vyhledávání nepodporuje. Rovněž nepoužívejte návěští phnk, ale jeho alternativu.Zvýraznění vyhledaných údajů pomocí dotazového pole
Údaje, které nejsou vyhledávány pomocí polí jsou zvýrazněny červeně v citaci článku i v textu článku. Údaje, které jsou vyhledávány pomocí návěští (polí) nejsou zvýrazněny červeně, jsou obsaženy v citaci článku. Spíše než návěští doporučujeme používat formulář s implicitně nastavenými poli.
B.1.2.1.6.3.2 Formulářová pole s implicitními údaji v rozšířených formulářích
Tabulka formulářových polí a metodika vyhledávání v těchto polích viz Charakteristika databáze - Jak vyhledávat - Formuláře.
Jednotlivé údaje ze stejných polí nebo různých polí z rolovacího menu lze kombinovat pomocí operátorů and, or, not. Ve spodní části obrazovky je možno nastavit vyhledávání <contains> - pro vyhledání daných řetězců kdekoli v poli, tj. po slovech, nebo = vyžadujeme-li přesné znění řetězce. Pro přesná znění je lépe využívat rejstříky. Všeobecně je lépe nastavit operátor <contains>.Údaje, které jsou vyhledávány pomocí implicitních polí, nejsou zvýrazněny v plném textu červeně.
B.1.2.1.6.3.3 Vyhledávání pomocí topiků - Rozšířený formulář s tématy viz Charakteristika databáze - Jak vyhledávat - Formuláře.
Tématem se rozumí předem připravený složitý dotaz. Jedno nebo více témat je možno vybrat označením v seznamu v pravém pruhu od formuláře (maximálně 3 témata pomocí klávesy Ctrl). Témata lze kombinovat vzájemně mezi sebou i s dotazem v poli dotazu, resp. textu dotazu. Relace mezi tématy a poli je možné zaškrtnutím voleb příslušných voleb v pravé dolní části formuláře (volba and, or) Tématický dotaz může obsahovat stovky slov. Je vytvářen speciálním editorem, který umožňuje vložit logické a další operátory dotazovacího jazyka, provádí kontrolu syntaxe a umožňuje proto plně využít výhod pokročilého vyhledávacího systému TOPIC. Pro databázi ANL FULL jsou témata strukturována do tří úrovní: první obsahuje základní tématické oblasti, druhá skupiny témat v těchto oblastech, třetí obsahuje detailní témata ve skupinách témat. Z první úrovně nelze zatím vyhledávat, z druhé a třetí ano - tam, kde je topik nadefinován (označeno šipkou vpravo). Tématická nabídka bude v budoucnu postupně rozšiřována a témata upřesňována.Přehled dosud nadefinovaných/navržených topiků strukturovaných do tří úrovní viz Charakteristika databáze - Jak vyhledávat - Formuláře.
B.1.2.1.6.3.4 Rejstříky viz Charakteristika databáze - Jak vyhledávat - Rejstříky.
V rejstřících je možno listovat a vybrat výraz, podle kterého chceme vyhledávat. Tyto výrazy jsou hypertextově propojeny v citacích s metadaty, resp.údaji bibliografického popisu. Podle rejstříků doporučujeme vyhledávat údaje zejména týkající se předmětu dokumentu (předmětové kategorie,hesla - věcná a geografická, osoby, korporace, akce, klíčová slova, dokument/dílo). Vyhledané výrazy jsou v bibliografickém popisu, resp. metadatech, resp. citaci vyznačeny červeně.B.1.2.1.6.3.5 Některá doporučení, jak nejlépe vyhledávat
B.1.2.1.7 Výsledky vyhledávání, zobrazení, tisk (všechny formuláře) viz Charakteristika databáze .
B.1.2.1.7.1 Seznam výsledků (seznam článků)
Seznam vyhledaných dokumentů uvádí v záhlaví nadpis a údaje o výsledku hledání. Počet vyhledaných dokumentů na stránku je dán volbou v poli Výsl./str. V závislosti na této volbě se potom zobrazuje počet stran s možností listování.Druhy seznamu výsledků (seznam článků):
U jednotlivých článků zobrazeno vždy, resp. standardně (zleva): tři formáty pro zobrazení údajů o článku, skóre relevance, datum vydání, název článku, velikost plného textu.Seznam výsledků (názvů vyhledaných článků):
Třídění seznamu výsledků (názvů vyhledaných článků)
Skóre relevance, od které zobrazovat názvy článků)
Výsl./str. (počet článků na stranu)
Třídění: dle:
B.1.2.1.7.2 Zobrazení údajů o článku
B.1.2.1.7.2.1 Formáty zobrazení
Uživatelské formáty
Každý dokument je možné zobrazit ve třech uživatelských formátech/variantách :
B.1.2.1.7.2.2 Metadata
Ve všech variantách zobrazení je obsažena citace, resp. biliografické údaje, resp. metadata. Kompletní seznam metadat v uživatelském formátu, resp. citace viz Příloha 4:Př.1 :
|
Název: |
Cesta mezi hlavou a rukou |
|
|
Podnázev: |
Když některé věci nenapíšu, nikdy se je nedozvím, říká publicista a spisovatel Pavel Kosatík |
|
|
Hlavní autor: |
Pavel Kosatík |
|
|
Další autor: |
Karel Hvížďala |
|
|
Zdroj: |
Mladá fronta Dnes |
|
|
Zdroj-příl.: |
Ekonomika |
|
|
ISSN: |
1210-1168 |
|
|
Roč. |
12, č. 204 (1.9.2001), s. C/5 |
|
|
Rubrika: |
Kultura - Pohledy |
|
|
Předmět. ktg.: |
politika: politici |
|
|
literatura: česká literatura |
||
|
Hromadné sdělovací prostředky: novináři |
||
|
MDT: |
323-051, 070-051, 821.162.3-051 |
|
|
Osoba jako předmět: |
Masaryk, Jan, 1886-1948 |
|
|
Peroutka, Ferdinand, 1895-1978 |
||
|
Kohout, Pavel, 1928- |
||
|
Téma jako předmět: |
Politici-Československo-stol. 20. |
|
|
|
Novináři-Československo-stol. 20. |
|
|
|
Spisovatelé-Československo-stol. 20. |
|
|
Typ dokumentu: |
Rozhovory |
|
Př. 2
:
|
Název: |
Rafinovaný odraz skutečnosti |
|
|
Podnázev: |
Na pultech se objevil další titul singerovské řady |
|
|
Hlavní autor: |
Hana Ulmanová |
|
|
Zdroj: |
Respekt |
|
|
ISSN: |
0862-6545 |
|
|
Roč. |
12, č. 41 (8.10.2001), s. 23 |
|
|
Rubrika: |
KULTURA |
|
|
Předmět. ktg.: |
literatura: americká literatura |
|
|
MDT: |
821.111(73)-31, (070.447) |
|
|
Osoba jako předmět: |
Singer, Isaac Bashevis, 1904-1991 |
|
|
Dílo jako předmět: |
Stíny nad Hudsonem (kniha) |
|
|
Téma jako předmět: |
Anglicky psaná literatura |
|
|
|
Americká próza |
|
|
|
Spisovatelé-Spojené státy-stol. 20. |
|
|
Typ dokumentu: |
Recenze |
|
Předkládá metodika vyhledávání je první verzí nápovědy pro vyhledávání v databázi ANL FULL. Bude se dále optimalizovat.
B.1.3 Standardizace - UNIMARC, DUBLIN CORE, HTML, XHTML, XML, propojení záznamů s plnými texty Struktura bibliografických dat respektuje formát UNIMARC a knihovnická pravidla AACR2 v oblasti jmenného popisu. V oblasti věcného popisu se používá aktualizovaná verze MDT-MRF . Verbální věcný popis obsahuje předmětové kategorie , které zasazují dokument do širších souvislostí v rámci databáze z hlediska obecných témat, jež by se měla sbližovat s tématy systému TOPIC. Předmětové kategorie do jisté míry konvenují metodě konspektu aplikované pro popis a mapování fondů. Dále se používají klíčová slova, která jsou dále částečně řízená a předmětová hesla. Automaticky je generován souhrn článku, automaticky lze také generovat klíčová slova, která však mají v současném stádiu "počítačovou formu". V budoucnu lze předpokládat i automatické generování termínů předmětové indexace. Tyto forma však vyžaduje intenzivní vývoj řízených slovníků/heslářů či tezaurů a jejich integraci do "subject gateways".Dublin Core obsahuje 14 z 15 definovaných údajů. Je generován pro
formát HTML, XHTML a XML ve kvalifikované i nekvalifikované formě. Do HTML je
zabudován LINK tag pro potřeby odkazu na webovský zdroj, v němž se
nachází specifikace daného použitého soboru metadat. Bylo nadefinováno 15 údajů
Anl Core vzhledem k detailnosti popisu a vzhledem k možnostem vyhledávání
v současné verzi systému TOPIC.
Formáty zobrazení jsou popsány dříve.
Hlavní řešitelka projektu se zúčastnila zasedání SDRUK, sekce pro bibliografii, kde byla diskutována problematika funkce KOSABI v době přechodu některých knihoven na krajskou úroveň a vzájemných vazeb v KOSABI. Bylo konstatováno, že krajské knihovny v nových krajích nejsou na spolupráci připraveny, resp. personálně vybaveny.
Pro rok 2001 bude zachována kompetence stávajících SVK, resp. krajských knihoven v rozsahu regionů před územní reformou.V r. 2001 byl nadefinován formát pro bázi titulů. K tomuto účelu byl modifikován formát SHORT SK CASLIN.
Zdroj katalogizace: [801b].[801c]
Sigla vlastnika: [910a].[910a]
Region: [952a].[952a]
Údaje o excerpci: [980a].[980b].[980c].[980k].[980p].[980r]
C.2 Závěr
Výsledkem řešení projektu v r. 2001 nové pojetí serveru FULL.NKP.CZ a způsobu vyhledávání v plnotextové databázi ANL FULL (vyhledávání pomocí metadat, rejstříků, topiků). Báze vzniká v rámci linky automatické indexace plných textů za současného generování formátů pro zpřístupnění elektronických dokumentů a bibliografických záznamů pro bázi ANL. Aplikace umožňuje přípravu importního souboru bibliografických záznamů (s automaticky generovanou URL adresou) pro ALEPH a jiné systémy, založené na UNIMARCu a doplnění plných textů o metadata Dublin Core v HTML, XHTML, XML.Po úspěšném experimentálním odzkoušení systému automatické indexace v r.
2001 je možno zahájit poloprovoz systému v r. 2002.
C.3 Návrhy opatření
D Použití finančních prostředků
D.1 Komentář
Komentář ke konečnému použití finančích prostředků je upraven oproti původní zprávě, protože ta se podávala k datu 15.11.2001. Čerpání finančních prostředků je v konečném vyúčtování projektu zohledňeno v tabulkách a doloženo fakturami.
| Výše státní dotace: | 1 056 000.- |
| Neinvestiční prostředky: | 1 015 000.- |
| Služby | 924 000.- |
| Mzdové prostředky | 91 000.- |
| Investiční prostředky: | 41 000.- |
| Národní knihovna ČR - odd. analytického zpracování | 200 000.- |
| Anopress, s.r.o. | 120 000.- |
Použití finančních prostředků je zohledněno v následujících tabulkách. První
z nich zachycuje využití neinvestičních prostředků. V rámci neinvestičních
prostředků jsou odděleny placené služby, materiál, mzdy. Druhá zachycuje
použití investic.
V tomto roce nebyla realizována plánovaná zahraniční stáž z důvodu
pracovního vytížení řešitelského týmu a prospěšnosti investovat ušetřené
prostředky do jiných typů služeb.
Plánované čerpání finančních neinvestic do konce roku 2001 je zachyceno
kurzívou.
Vzhledem k tomu, že projekt je velmi náročný koncepčně i realizačně zároveň, je vklad hlavní řešitelky a pracovníků oddělení poměrně velký.
E Resumé a klíčová slova
E.1 Resumé a klíčová slova v češtině
Resumé:
Náplní projektu je optimalizace integrace a správy heterogenních dat souborné databáze Kooperačního systému článkové bibliografie (KOSABI). Bibliografické záznamy článků, publikovaných v českém periodickém tisku a zpracovávané spolupracujícími knihovnami, jsou postupně propojované s elektronickou podobou článku a takto prezentované na Internetu.15. listopadu 2001
PhDr. Vojtěch Balík, ředitel NK
PhDr. Ivana Anděrová, hlavní řešitelka